

Reactor에서의 디버깅 방법
Reactor는 처리되는 작업들이 대부분 비동기적으로 실행되고, Reactor Sequence는 선언형 프로그래밍 방식으로 구성되므로 디버깅이 쉽지 않습니다.
이러한 디버깅의 어려움을 최소화하기 위해 Reactor에서는 몇 가지 방법을 제공합니다.
1. Debug Mode를 사용한 디버깅
Reactor에서는 디버그 모드(Debug Mode)를 활성화해서 Reactor Sequence를 디버깅할 수 있습니다.
@Slf4j
public class DemoApplication {
public static Map<String, String> fruits = new HashMap<>();
static {
fruits.put("banana", "바나나");
fruits.put("apple", "사과");
fruits.put("pear", "배");
fruits.put("graph", "포도");
}
public static void main(String[] args) throws InterruptedException {
// Hooks.onOperatorDebug();
Flux
.fromArray(new String[]{"BANANAS", "APPLES", "PEARS", "MELONS"})
.subscribeOn(Schedulers.boundedElastic())
.publishOn(Schedulers.parallel())
.map(String::toLowerCase)
.map(fruit -> fruit.substring(0, fruit.length() - 1))
.map(fruits::get)
.map(translate -> "맛있는 " + translate)
.subscribe(
log::info,
error -> log.error("# onError : ", error)
);
Thread.sleep(100L);
}
}
Reactor에서의 디버그 모드 활성화는 `Hooks.onOperatorDebug()` 를 통해서 이루어집니다.
우선 주석 처리하여 디버그 모드를 활성화하지 않을 경우의 에러 출력을 확인해봅시다.
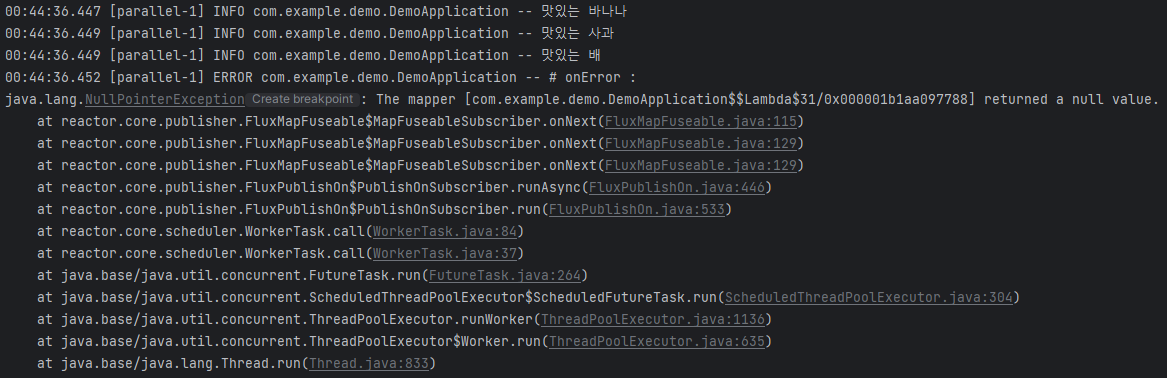
출력된 에러 메시지(NullPointerException) 이외의 stack trace에서는 의미 있는 내용을 확인하기가 어렵습니다. 에러 메시지를 확인해보면, `map()` Operator에서 NullPointerException이 발생한 것 같기는 하지만, 위 코드에는 `map()` 이 4 개나 있기 때문에 어떤 `map()` Operator에서 에러가 발생했는지 구체적으로 알기 힘듭니다.
그럼 이제 주석을 해제한 후, 코드를 다시 실행해 봅시다.
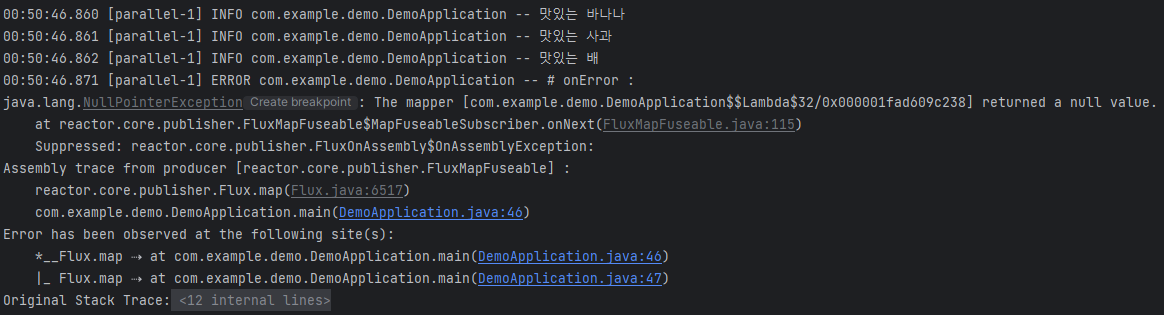
첫 번째 결과와 비교 했을 때 추가된 내용들을 보면, Operator 체인상에서 에러가 발생한 지점을 정확히 가리키고 있으며, 에러가 시작된 지점부터 에러 전파 상태를 표시해 주고 있습니다. 이 내용을 확인해 에러 원인을 분석하면 됩니다.
이처럼 Operator 체인이 시작되기 전에 디버그 모드를 활성화하면 에러가 발생한 지점을 좀 더 명확하게 찾을 수 있습니다.
Hooks.onOperatorDebug( ) 사용의 한계
디버그 모드의 활성화는 다음과 같이 애플리케이션 내에서 비용이 많이 드는 동작 과정을 거칩니다.
- 애플리케이션 내에 있는 모든 Operator의 Stacktrace를 캡쳐한다.
- 에러가 발생하면 캡쳐한 정보를 기반으로 에러가 발생한 Assembly의 Stacktrace를 원본 Stacktrace 중간에 끼워 넣는다.
따라서,
에러 원인을 추적하기 위해 처음부터 디버그 모드를 활성화하는 것은 권장하지 않습니다.
Assembly
Operator에서 리턴하는 새로운 Mono 또는 Flux가 선언된 지점
2. checkpoint() Operator를 사용한 디버깅
특정 Operator 체인 내의 Stacktrace만 캡쳐
합니다.
Traceback을 출력하는 방법
Traceback이란,
에러가 발생한 Operator의 Stacktrace를 캡쳐한 Assembly 정보
를 말합니다.
`checkpoint()` Operator를 사용하면 실제 에러가 발생한 assembly 지점 또는 에러가 전파된 assembly 지점의 traceback이 추가됩니다.
@Slf4j
public class DemoApplication {
public static void main(String[] args) throws InterruptedException {
Flux
.just(2, 4, 6, 8)
.zipWith(Flux.just(1, 2, 3, 0), (x, y) -> x / y)
// .checkpoint()
.map(num -> num + 2)
.checkpoint()
.subscribe(
data -> log.info("# onNext: {}", data),
error -> log.error("# onError:", error)
);
}
}
위 코드에서 `map` 바로 다음 위치에 `checkpoint()` 를 추가했는데, 실행 결과는 다음과 같습니다.
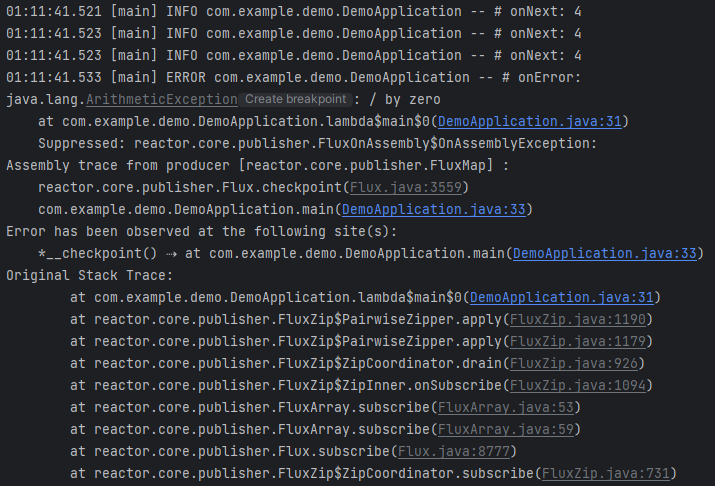
5번 라인을 통해 ArithmeticException이 발생한 것을 알 수 있습니다. 아직은 에러가 직접적으로 발생한 지점인지 아니면 에러가 전파된 지점인지 정확히 알 수 없습니다. 하지만, 12번 라인을 통해 `map()` 다음에 추가한 `checkpoint()` 지점까지는 에러가 전파되었다는 것을 예상할 수 있습니다.
에러가 예상되는 지점을 정확하게 찾기 위해 중간의 `checkpoint()` 주석을 해제하고 다시 샐행해 봅시다.

실행 결과를 확인해보면 두 `checkpoint()` 모두 Traceback이 출력된 것을 확인할 수 있습니다. 첫 번째 `checkpoint()` 는 `zipWith()` Operator에서 직접적으로 에러가 발생해 출력된 것이고, 두 번째 `checkpoint()` 는 에러가 전파되었기 때문에 출력된 것입니다.
Traceback 출력 없이 식별자를 포함한 Description을 출력해서 에러 발생 지점을 예상하는 방법
`checkpoint(description)` 을 사용하면
에러 발생 시 Traceback을 생략하고 description을 통해 에러 발생 지점을 예상
할 수 있습니다.
@Slf4j
public class DemoApplication {
public static void main(String[] args) {
Flux
.just(2, 4, 6, 8)
.zipWith(Flux.just(1, 2, 3, 0), (x, y) -> x / y)
.checkpoint("zipWith.checkpoint")
.map(num -> num + 2)
.checkpoint("map.checkpoint")
.subscribe(
data -> log.info("# onNext: {}", data),
error -> log.error("# onError:", error)
);
}
}
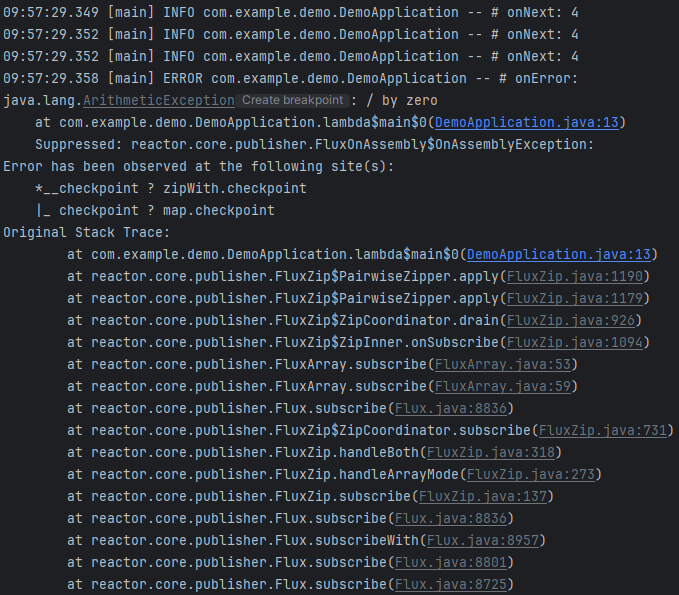
`checkpoint()` 에 description을 추가해 Traceback 대신에 description을 출력하게 할 수 있습니다.
Traceback과 Description을 모두 출력하는 방법
checkpoint(description, forceStackTrace)
`checkpoint(description, forceStackTrace)` 를 사용하면
description과 Traceback을 모두 출력
할 수 있습니다.
@Slf4j
public class DemoApplication {
public static void main(String[] args) {
Flux
.just(2, 4, 6, 8)
.zipWith(Flux.just(1, 2, 3, 0), (x, y) -> x / y)
.checkpoint("zipWith.checkpoint", true)
.map(num -> num + 2)
.checkpoint("map.checkpoint", true)
.subscribe(
data -> log.info("# onNext: {}", data),
error -> log.error("# onError:", error)
);
}
}
위 코드와 같이 두 번째 파라미터를 ‘true’로 설정하면 에러 발생 시 description과 Traceback을 모두 출력할 수 있습니다.
위의 코드들처럼 Operator 체인이 단순하다면 checkpoint()를 추가하지 않더라도 에러를 직접 찾을 수 있지만, 조금 복잡해지면 에러 발생 지점을 찾는 것이 쉽지 않습니다. 또한, Operator 체인이 기능별로 여러 곳에 흩어져 있는 경우, checkpoint()를 적절히 활용하면, 범위를 좁혀가며 단계적으로 에러 발생 지점을 찾을 수 있습니다.
3. log() Operator를 사용한 디버깅
`log()` Operator는
Reactor Sequence의 동작을 로그로 출력
합니다. 그리고 이 로그를 통해 디버깅이 가능합니다.
@Slf4j
public class DemoApplication {
public static Map<String, String> fruits = new HashMap<>();
static {
fruits.put("banana", "바나나");
fruits.put("apple", "사과");
fruits.put("pear", "배");
fruits.put("graph", "포도");
}
public static void main(String[] args) throws InterruptedException {
Flux
.fromArray(new String[]{"BANANA", "APPLES", "PEARS", "MELONS"})
.map(String::toLowerCase)
.map(fruit -> fruit.substring(0, fruit.length() - 1))
.log()
.map(fruits::get)
.subscribe(
log::info,
error -> log.error("# onError : ", error)
);
}
}
위 코드에서 두 번째 `map()` Operator 다음에 `log()` Operator를 추가했습니다.
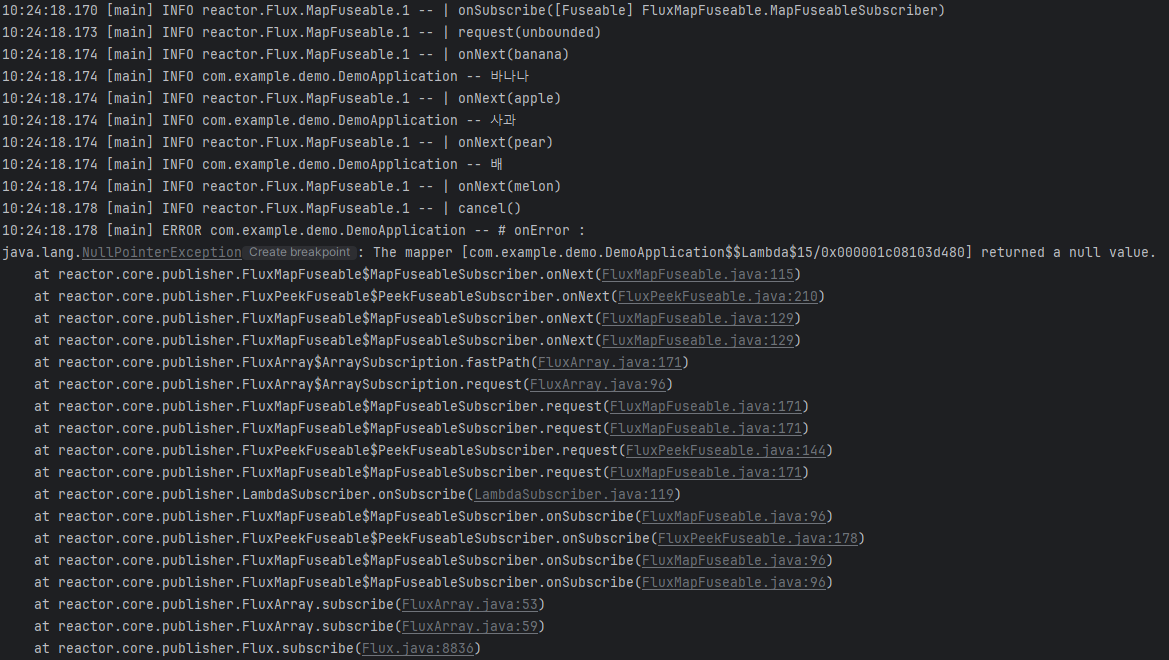
실행 결과에서 Subscriber에 전달된 결과 이외에 `onSubscribe()`, `request()`, `onNext()` 같은 Signal이 출력된 것을 확인할 수 있습니다. 이 Signal들은 두 번째 map() Operator에서 발생한 Signal들입니다.
실행 결과에서 마지막으로 `cancel()` Signal이 출력되었습니다. 이는 두 번째 `map`이 “melon”이라는 문자열을 emit했지만, 이 이후에 처리하는 중에 에러가 발생했음을 의미합니다.
위 코드에서는 두 번째 `map` 이후에 `map`이 하나밖에 없기 때문에 여기서 문제가 발생했음을 알 수 있습니다.
하지만 위의 방법은 로그의 로그 레벨이 모두 똑같아, 분석하기 쉽지 않습니다. 따라서 `log()` Operator를 `.log("Fruit.Substring", Level.FINE)` 과 같이 바꾸어 실행할 수 있습니다.
Level.FINE은 java에서 지원하는 로그 레벨이며, Slf4j 로깅 프레임워크에서 사용하는 로그 레벨 중 DEBUG 레벨에 해당됩니다.
이처럼 `log()` Operator를 사용하면
에러가 발생한 지점에 단계적으로 접근할 수 있습니다.
참고
"스프링으로 시작하는 리액티브 프로그래밍"
'스프링(Spring) > WebFlux' 카테고리의 다른 글
| [Spring/WebFlux] Context (1) | 2024.02.29 |
|---|---|
| [Spring/WebFlux] Sinks (0) | 2024.02.22 |
| [Spring/WebFlux] Backpressure (0) | 2024.02.20 |
| [Spring/WebFlux] Cold Sequence와 Hot Sequence (1) | 2024.02.20 |
| [Spring/WebFlux] 마블 다이어그램(Marble Diagram)으로 보는 Mono & Flux (0) | 2024.02.14 |