

Backpressure 란?
Backpressure는 우리말로 배압 또는 역압이라고 합니다. 배관으로 유입되는 가스나 액체 등의 흐름을 제어하기 위해 역으로 가해지는 압력을 의미합니다.
리액티브 프로그래밍에서는 Publisher가 끊임없이 emit 하는 무수히 많은 데이터를 적절하게 제어해 데이터 처리에 과부하가 걸리지 않도록 제어하는 것이 Backpressure의 역할입니다.
Publisher가 data 1부터 N까지를 emit하는 상황을 생각해봅시다.
먼저, Publisher가 data 1을 Subscriber에서 emit 합니다. 하지만, Subscriber가 data 1을 처리하는 속도가 느려서 처리가 끝나기도 전에, Publisher는 data 2부터 data N까지 계속해서 emit하게 됩니다. 이럴 경우, emit 된 데이터들은 Subscriber가 data 1을 처리 완료하기 전까지 대기하게 됩니다.
이렇게 하지 않고, Publisher가 빠른 속도로 데이터를 끊임없이 emit하게 된다면, 처리되지 않고 대기 중인 데이터가 지속적으로 쌓이게 되어 오버플로가 발생하거나 시스템이 다운되는 문제가 발생할 수 있습니다.
Reactor에서의 Backpressure 처리 방식
Reactor에서는 다양한 방식으로 Backpressure를 지원합니다. 지금부터 하나씩 그 유형을 살펴보겠습니다.
데이터 개수 제어
첫 번째 방식은
Subscriber가 적절히 처리할 수 있는 수준의 데이터 개수를 Publisher에게 요청하는 것
입니다. 이때, Subscriber가 `request()` 메서드를 통해 적절한 데이터 개수를 요청하는 방식을 이용합니다.
@Slf4j
public class DemoApplication {
static final Logger log = LoggerFactory.getLogger(DemoApplication.class);
public static void main(String[] args) {
Flux.range(1, 5)
.doOnRequest(data -> log.info("# doOnRequest: {}", data))
.subscribe(new BaseSubscriber<Integer>() {
@Override
protected void hookOnSubscribe(Subscription subscription) {
request(1);
}
@SneakyThrows
@Override
protected void hookOnNext(Integer value) {
Thread.sleep(2000L);
log.info("# hookOnNext: {}", value);
request(1);
}
});
}
}위 코드는 Subscriber가 데이터의 요청 개수를 조절하는 Backpressure에 대한 예제입니다.
Reactor에서는 Subscriber가 데이터 요청 개수를 직접 제어하기 위해서 Subscriber 인터페이스의 구현 클래스인 `BaseSubscriber` 를 사용할 수 있습니다.
BaseSubscriber
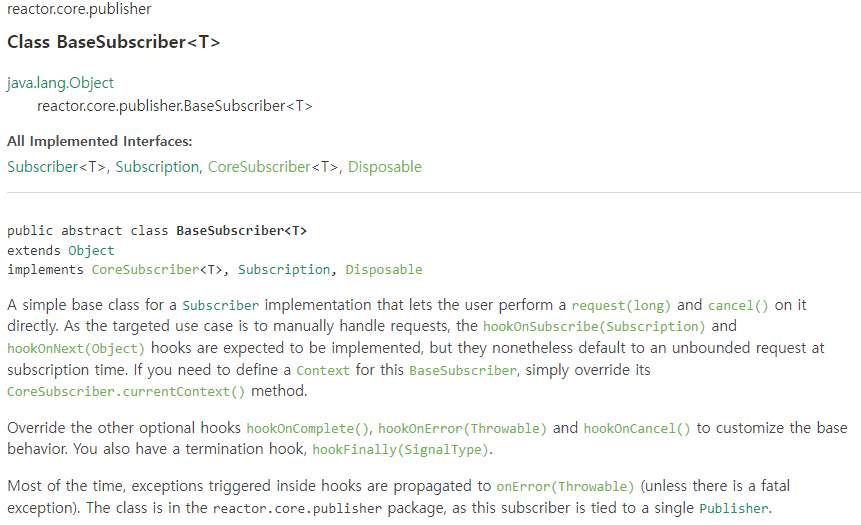
위 그림은 Reactor의 Documentation에 나와있는 BaseSubscriber에 대한 설명입니다. 첫 줄을 보면, 사용자가 `request()`와 `cancel()`을 사용할 수 있도록 Subscriber 인터페이스를 구현하기 위한 가장 간단한 base class라는 것을 확인할 수 있습니다.
- `subscribe()` 메서드의 파라미터로 람다 표현식 대신 `BaseSubscriber` 객체를 전달합니다.
- `hookOnSubscribe()` := Subscriber 인터페이스에 정의된 `onSubscribe()` 메서드를 대신해 구독 시점에 `request()` 메서드를 호출해서 최초 데이터 요청 개수를 제어하는 역할
- `hookOnNext()` := Subscriber 인터페이스에 정의된 `onNext()` 메서드를 대신해 Publisher가 emit한 데이터를 전달받아 처리한 후에 Publisher에게 또다시 데이터를 요청하는 역할. 이때 역시 `request()` 메서드를 호출해서 데이터의 요청 개수를 제어

실제로, `BaseSubscriber` 객체를 살펴보면 위와 같이 정의되어 있는 것을 확인할 수 있습니다.
다시, 위 예시 코드로 돌아가보면, `range()` Operator를 사용해 1부터 1씩 증가한 5개의 데이터를 emit하도록 정의되었습니다. 그리고 `BaseSubscriber`가 데이터를 1개씩 보내주기를 Publisher에게 요청합니다. 그리고, emit 속도보다 Subscriber의 데이터 처리 속도가 느린 것을 시뮬레이션하기 위해 `hookOnNext()` 메서드 내부에서 2초 지연 시간을 주었습니다.
실행 결과는 다음과 같습니다.

1부터 5까지 다섯 개의 숫자를 출력하는 것을 볼 수 있습니다. "# doOnRequest: 1"은 `BaseSubscriber`가 데이터를 몇 개씩 요청하는지 확인하기 위한 로그입니다. `doOnRequest()` Operator를 사용해 Subscriber가 요청한 데이터의 요청 개수를 로그로 출력할 수 있습니다.
따라서, "# doOnRequest: 1"은 `hookOnSubscribe()` 메서드에서 `request()` 메서드를 호출함으로써 출력된 결과이고, 나머지 "# doOnRequest: 1"은 모두 `hookOnNext()` 메서드에서 `request()` 메서드를 호출함으로써 출력된 결과입니다.
결과적으로, 데이터의 요청 개수를 직접적으로 제어하는 Backpressure 방식을 사용할 필요가 있을 경우, 위와 같이 `BaseSubscriber`를 사용해 데이터 요청 개수를 제어할 수 있습니다.
참고)
위 코드의 @SneakyThrows는 메서드 선언부에 Throws를 정의하지 않고도, 검사 된 예외를 Throw 할 수 있도록 하는 Lombok에서 제공하는 어노테이션입니다. 즉, throws나 try-catch 구문을 통해 Exception에 대해 번거롭게 명시적으로 예외 처리를 해야하는 경우 @SneakyThrows 어노테이션을 사용해 명시적인 예외 처리를 생략할 수 있습니다.
Backpressure 전략 사용
두 번째 Backpressure 방식은 Reactor에서 제공하는 Backpressure 전략을 사용하는 것입니다. 우선, 표를 통해 간단히 살펴 보겠습니다.
| 종류 | 설명 |
| IGNORE 전략 | Backpressure를 적용하지 않는다. |
| ERROR 전략 | Downstream으로 전달할 데이터가 버퍼에 가득 찰 경우, Exception을 발생시키는 전략 |
| DROP 전략 | Downstream으로 전달할 데이터가 버퍼에 가득 찰 경우, 버퍼 밖에서 대기하는 먼저 emit된 데이터부터 Drop 시키는 전략 |
| LATEST 전략 | Downstream으로 전달할 데이터가 버퍼에 가득 찰 경우, 버퍼 밖에서 대기하는 가장 최근에(나중에) emit된 데이터부터 버퍼에 채우는 전략 |
| BUFFER 전략 | Downstream으로 전달할 데이터가 버퍼에 가득 찰 경우, 버퍼 안에 있는 데이터부터 Drop 시키는 전략 |
IGNORE 전략
IGNORE 전략은 말 그대로
Backpressure를 적용하지 않는 전략
입니다. 이 전략을 사용할 경우, Downstream에서의 Backpressure 요청이 무시되기 때문에 IllegalStateException이 발생할 수 있습니다.
ERROR 전략
ERROR 전략은
Downstream의 데이터 처리 속도가 느려서 Upstream의 emit 속도를 따라가지 못할 경우 IllegalStateException을 발생시키는 전략
입니다. 이 경우, Publisher는 Error Signal을 Subscriber에게 전송하고 삭제한 데이터는 폐기합니다.

@Slf4j
public class DemoApplication {
static final Logger log = LoggerFactory.getLogger(DemoApplication.class);
public static void main(String[] args) throws InterruptedException {
Flux
.interval(Duration.ofMillis(1L))
.onBackpressureError()
.doOnNext(data -> log.info("# doOnNext: {}", data))
.publishOn(Schedulers.parallel())
.subscribe(data -> {
try {
Thread.sleep(5L);
} catch (InterruptedException e) { }
log.info("# onNext: {}", data);
},
error -> {
log.error("# onError");
error.printStackTrace();
});
Thread.sleep(2000L);
}
}위 코드는 ERROR 전략을 사용한 예시입니다.
- `interval()` Operator를 사용해 0부터 1씩 증가한 숫자를 0.001초에 한 번씩 아주 빠른 속도로 emit하도록 정의합니다.
참고로, `interval()`의 마블 다이어그램은 아래의 그림과 같습니다. - Subscriber가 전달받은 데이터를 처리하는 데 0.005초가 걸리도록 설정했습니다. 이렇게 구성하면 Publisher에서 데이터를 emit하는 속도와 Subscriber가 전달받은 데이터를 처리하는 속도에 차이가 나서 Backpressure 전략의 테스트가 가능해집니다.
- ERROR 전략을 사용하기 위해 `onBackpressureError()` Operator를 사용했습니다. `doOnNext()` Operator는 Publisher가 emit 한 데이터를 확인(디버깅)하거나 추가적인 동작을 정의하는 용도로 사용됩니다.
- `publishOn()` Operator는 Reactor Sequence 중 일부를 별도의 스레드에서 실행할 수 있도록 해 주는 Operator입니다. 쉽게 생각하면 별도의 스레드가 하나 더 실행된다고 생각하면 됩니다. 아래의 실행 결과를 보면 parallel로 시작하는 스레드가 두 개가 실행되는 것을 확인할 수 있습니다.

위 코드의 실행 결과는 다음과 같습니다.





출력 길이가 길어 데이터를 확인할 수 있는 부분을 잘라 첨부했습니다.
결과를 보면, `doOnNext()` 에서 출력한 로그에서 Publisher가 거의 0.0001초에 한 번씩 데이터를 emit하는 것을 확인할 수 있습니다. 그리고 Subscriber에서 데이터를 처리하는 `onNext` 람다 표현식에서는(`subscribe()` 안의 코드) 0.005초에 한 번씩 로그를 출력하다가 255라는 숫자를 출력하고 OverflowException이 발생하면서 Sequence가 종료되는 것을 확인할 수 있습니다.
DROP 전략
DROP 전략은
Publisher가 Downstrea으로 전달할 데이터가 버퍼에 가득 찰 경우, 버퍼 밖에서 대기 중인 데이터 중에서 먼저 emit된 데이터부터 Drop시키는 전략
입니다. Drop된 데이터는 폐기됩니다.
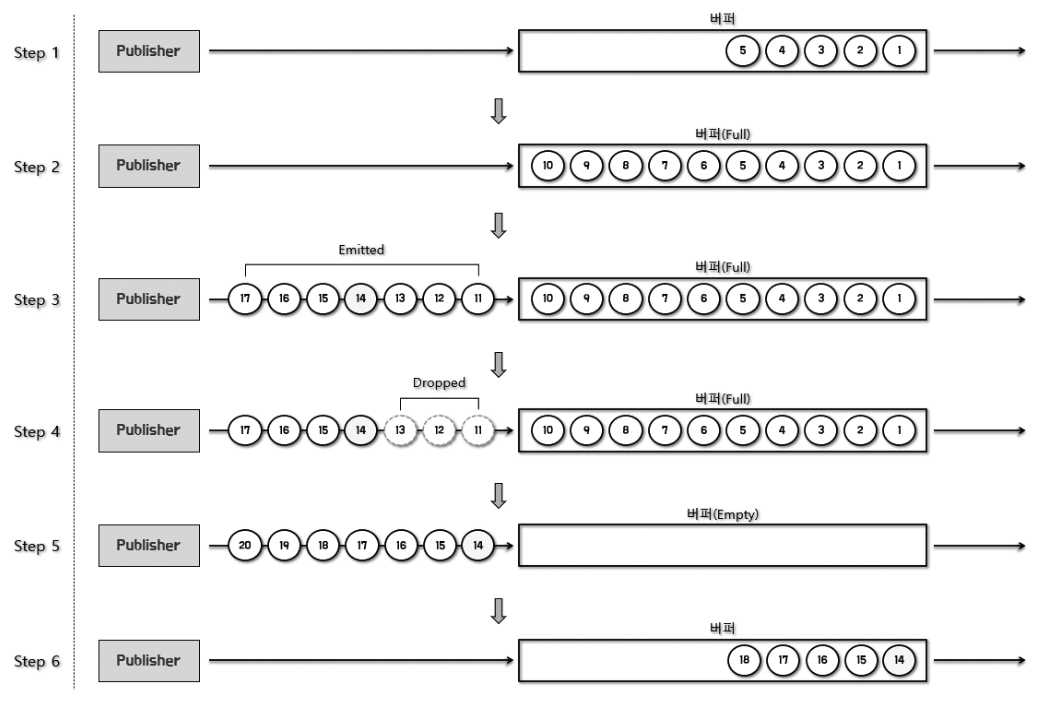
위 그림에 대한 설명은 다음과 같습니다.
- Step 1 := Publisher가 emit한 데이터가 버퍼에 채워지고 있습니다.
- Step 2 := 버퍼에 데이터가 가득 찼습니다.
- Step 3 := 그 와중에 데이터가 계속 emit 되고 있으며, 버퍼가 가득 찼기 때문에 버퍼 밖에서 대기하는 상황이 됩니다.
- Step 4 := Downstream에서 데이터 처리가 아직 끝나지 않아 버퍼가 비어 있지 않은 상태이기 때문에 버퍼 밖에서 대기 중인 먼저 emit된 숫자 11, 12, 13이 Drop 되고 있습니다.
→ Step 3과 4는 사실 동일한 과정의 연속입니다. - Step 5 := Downstream에서 데이터 처리가 끝나서 버퍼를 비운 상태입니다. 버퍼가 비었기 때문에 숫자 14는 Drop 되지 않고 버퍼에 채워질 것입니다.
- Step 6 := Drop되지 않은 숫자 14부터 버퍼에 채워지고 있습니다.

Drop 전략을 코드를 통해 살펴봅시다.
@Slf4j
public class DemoApplication {
static final Logger log = LoggerFactory.getLogger(DemoApplication.class);
public static void main(String[] args) throws InterruptedException {
Flux
.interval(Duration.ofMillis(1L))
.onBackpressureDrop(dropped -> log.info("# dropped: {}", dropped))
.publishOn(Schedulers.parallel())
.subscribe(data -> {
try {
Thread.sleep(5L);
} catch (InterruptedException e) { }
log.info("# onNext: {}", data);
},
error -> {
log.error("# onError");
error.printStackTrace();
});
Thread.sleep(2000L);
}
}위의 ERROR 전략 코드와 비슷하지만, `onBackpressureError()` 대신 `onBackpressureDrop()`을 사용해 Backpressure 전략만 DROP으로 바꾸었습니다.
`onBackpressureDrop()` Operator는 Drop된 데이터를 파라미터로 전달받을 수 있기 때문에 Drop된 데이터가 폐기되기 전에 추가 작업을 수행할 수 있습니다.
실행 결과는 아래와 같습니다.
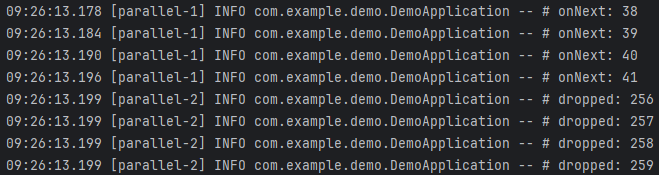
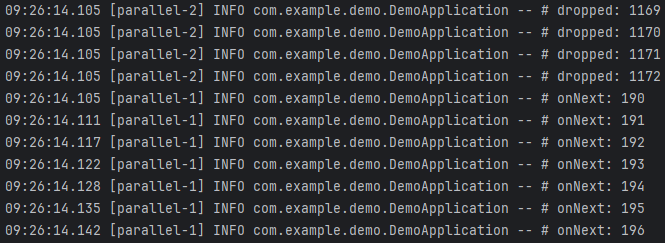
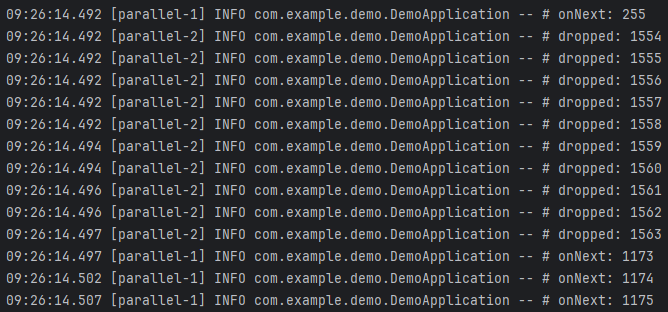
위 결과를 살펴보면, Drop이 시작되는 데이터는 숫자 256입니다(첫 번째 사진). 그리고 Drop이 끝나는 데이터는 숫자 1172입니다(두 번째 사진). 이 구간 동안에는 버퍼가 가득 차 있는 상태입니다. 따라서, 세 번째 사진을 보면 버퍼에 들어있는 마지막 숫자인 255의 처리가 끝나고 Drop이 끝난 숫자 1172의 다음 숫자인 1173부터 전달받아 처리하는 것을 볼 수 있습니다.
이처럼 DROP 전략을 적용하면 버퍼가 가득 찬 상태에서는 버퍼가 비워질 때까지 데이터를 Drop합니다.
LATEST 전략
LATEST 전략은
Publisher가 Downstream으로 전달할 데이터가 버퍼에 가득 찰 경우, 버퍼 밖에서 대기 중인 데이터 중에서 가장 최근(나중)에 emit된 데이터부터 버퍼에 채우는 전략
입니다.
앞서 본, DROP 전략은 대기 중인 데이터를 하나씩 차례대로 Drop하면서 폐기하지만, LATEST 전략은 새로운 데이터가 들어오는 시점에 가장 최근의 데이터만 남겨 두고 나머지 데이터를 폐기합니다.

위 그림을 살펴 봅시다.
- Step 1 := Publisher가 emit한 데이터가 버퍼에 채워지고 있습니다.
- Step 2 := 버퍼가 가득 찼습니다.
- Step 3 := 버퍼가 가득 찬 상태에서 데이터가 계속 emit되어 버퍼 밖에서 대기합니다.
- Step 4 := Downstream에서 데이터 처리가 끝나 버퍼를 비운 상태입니다. 버퍼가 비었기 때문에 가장 최근(나중)에 emit된 숫자 17부터 버퍼에 채워지고 나머지 데이터는 폐기됩니다.
- Step 5 := 숫자17부터 버퍼에 채워지고 있습니다. 실제로는 그림처럼 17 이외의 숫자들이 한꺼번에 폐기되는 것이 아니라, 데이터가 들어올 때마다 이전에 유지하고 있던 데이터가 폐기됩니다.

코드로 살펴 봅시다.
@Slf4j
public class DemoApplication {
static final Logger log = LoggerFactory.getLogger(DemoApplication.class);
public static void main(String[] args) throws InterruptedException {
Flux
.interval(Duration.ofMillis(1L))
.onBackpressureLatest()
.publishOn(Schedulers.parallel())
.subscribe(data -> {
try {
Thread.sleep(5L);
} catch (InterruptedException e) { }
log.info("# onNext: {}", data);
},
error -> {
log.error("# onError");
error.printStackTrace();
});
Thread.sleep(2000L);
}
}`onBackpressureLatest()` Operator를 사용해 LATEST 전략을 적용한 것을 확인할 수 있습니다. 실행 결과는 아래와 같습니다.

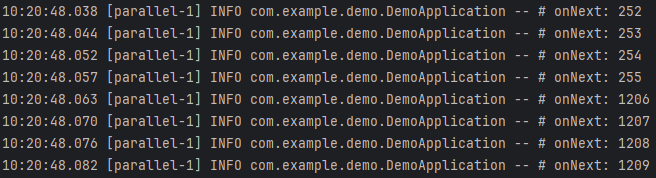
Subscriber가 0부터 255를 출력하고 다음 숫자로 1206을 출력하는 것을 볼 수 있습니다. 이는 버퍼가 가득 찼다가 버퍼가 다시 비워지는 시간 동안 emit되는 데이터가 가장 최근(나중)에 emit된 데이터가 된 후, 다음 데이터가 emit되면 다시 폐기되는 이 과정을 반복하기 때문입니다.
BUFFER 전략
BUFFER 전략은
1. 버퍼의 데이터를 폐기하지 않고 버퍼링을 하는 전략 지원
2. 버퍼가 가득 차면 버퍼 내의 데이터를 폐기하는 전략
3. 버퍼가 가득 차면 에러를 발생시키는 전략
과 같이 다양한 전략을 지원합니다. 위 전략 중에서 버퍼가 가득 찼을 때 버퍼 내의 데이터를 폐기하는 전략(2번)을 살펴보겠습니다.
생각해 볼 점은 DROP, LATEST 전략은 버퍼가 가득 차면 버퍼 "바깥쪽"의 데이터를 폐기하는 방식입니다. 하지만, BUFFER 전략에서의 데이터 폐기는 버퍼 안에 있는 데이터를 폐기하는 것을 의미합니다.
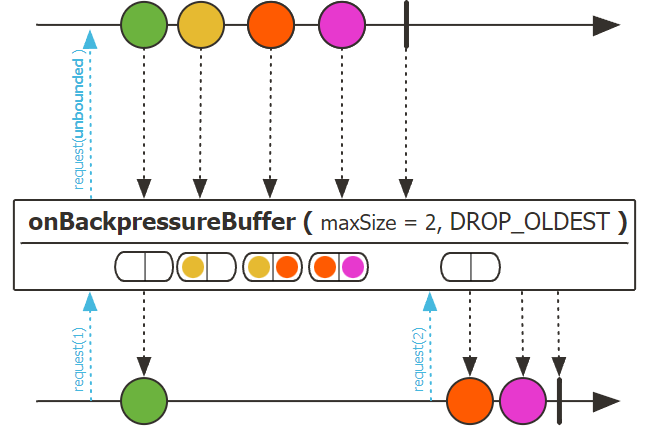
BUFFER 전략에는 DROP_LATEST 전략과 DROP_OLDEST 전략 이렇게 두 가지가 있습니다.
DROP_LATEST 전략
BUFFER DROP_LATEST 전략은
Publisher가 Downstream으로 전달할 데이터가 버퍼에 가득 찰 경우, 가장 최근(나중)에 버퍼 안에 채워진 데이터를 Drop해 폐기한 후, 이렇게 확보된 공간에 emit된 데이터를 채우는 전략
입니다.

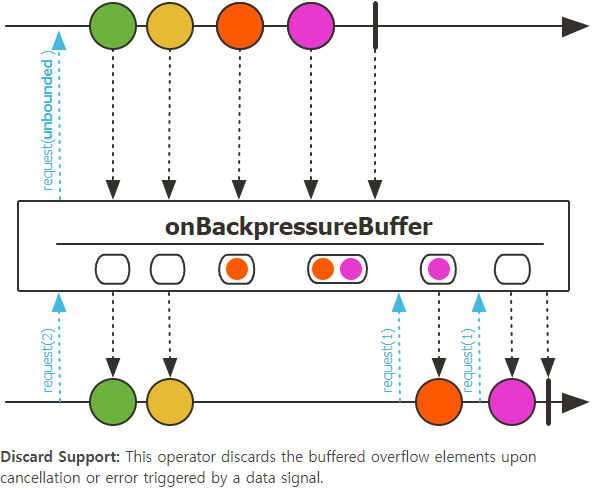
위 그림에서 버퍼의 최대 용량은 10이라고 가정하겠습니다.
- Step 1 := Publisher가 emit한 데이터가 버퍼에 채워지고 있습니다.
- Step 2 := 버퍼가 가득 찼습니다.
- Step 3 := 숫자 11이 emit되어 버퍼에 채워집니다. 이때 버퍼 오버플로가 발생합니다.
- Step 4 := 오버플로를 일으킨 숫자 11이 Drop 되어 폐기됩니다.
@Slf4j
public class DemoApplication {
static final Logger log = LoggerFactory.getLogger(DemoApplication.class);
public static void main(String[] args) throws InterruptedException {
Flux
.interval(Duration.ofMillis(300L))
.doOnNext(data -> log.info("# emitted by original Flux: {}", data))
.onBackpressureBuffer(2,
dropped -> log.info("** Overflow & Dropped: {} **", dropped),
BufferOverflowStrategy.DROP_LATEST)
.doOnNext(data -> log.info(" [ # emitted by Buffer: {} ]", data))
.publishOn(Schedulers.parallel(), false, 1)
.subscribe(data -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) { }
log.info("# onNext: {}", data);
},
error -> {
log.error("# onError");
error.printStackTrace();
});
Thread.sleep(3000L);
}
}BUFFER DROP_LATEST 전략을 사용한 코드입니다.
`onBackperessureBuffer()` Operator를 사용해 BUFFER 전략을 적용했는데, 각 파라미터는 다음과 같습니다.
- 첫 번째 파라미터 := 버퍼의 최대 용량(여기서는 2로 설정)
- 두 번째 파라미터 := 버퍼 오버플로가 발생했을 때, Drop되는 데이터를 전달받아 후처리
- 세 번째 파라미터 := 적용할 Backpressure 전략(여기서는 DROP_LATEST 전략 사용)
`publishOn()` Operator를 통해 스레드를 하나 더 추가하는데, 세 번째 파라미터에서 prefetch 수를 1로 지정했습니다. prefetch는 Scheduler가 생성하는 스레드의 비동기 경계 시점에 미리 보관할 데이터의 개수를 의미합니다.
첫 번째 `doOnNext()` Operator를 통해 원본 Flux, 즉 `interval()` Operator에서 생성된 원본 데이터가 emit되는 과정을 확인할 수 있습니다.
두 번째 `doOnNext()` Operator를 통해 Buffer에서 Downstream으로 emit되는 데이터를 확인할 수 있습니다.
실행 결과는 다음과 같습니다.
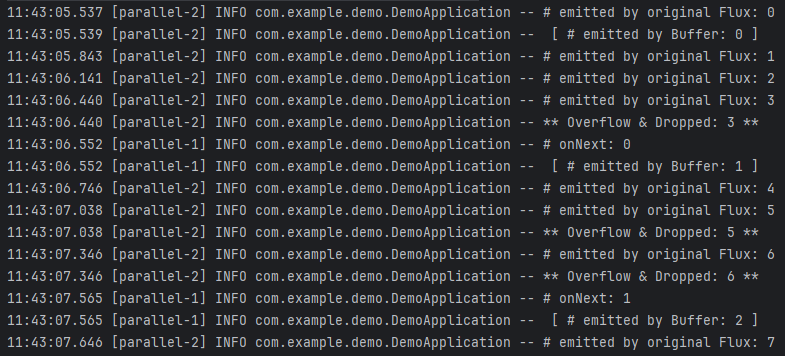
- 원본 Flux에서 숫자 0이 emit 되고, 버퍼에 잠시 채워진 다음 버퍼에서 다시 emit 됩니다. 이 시점에서의 버퍼는 비어있는 상태인데, 버퍼의 상태는 [ ]로 표시하겠습니다.
- 원본 Flux가 emit한 숫자 0을 Subscriber가 처리하기까지 1초 정도의 시간이 걸립니다. `Thread.sleep(1000L)`으로 설정했기 때문입니다. 따라서, 7번 라인에서 "# onNext"가 출력되는 것을 확인할 수 있습니다.
- Subscriber가 숫자 0을 처리하는 1초의 시간 동안 원본 Flux에서는 0.3초에 한 번씩 숫자 1, 2를 emit합니다(`interval()`의 시간을 300ms로 설정했기 때문에, 0.3초마다 데이터를 emit합니다). 버퍼의 최대 용량이 2이기 때문에 이 시점에 버퍼에는 1, 2가 채워져 버퍼 상태는 [ 2, 1 ]입니다.
- 0.3초 뒤에 원본 Flux에서 숫자 3을 emit합니다. 그런데 이 시점에 버퍼 안에 숫자 3이 채워지는 순간, 버퍼 오버플로가 발생해 숫자 3이 Drop되게 됩니다. 이 시점에 버퍼 상태는 여전히 [ 2, 1 ] 입니다.
- 그리고 버퍼에서 숫자 1이 emit 됩니다. 이 시점에서 버퍼 상태는 [ 2 ] 입니다.
- 다시 Subscriber가 숫자 1을 처리하는 1초 동안(11:43:06.552 ~ 11:43:07.565), 원본 Flux에서는 숫자 4를 emit해 버퍼에 채워집니다. 버퍼의 상태는 [ 4, 2 ]가 되겠네요.
- 0.3초 뒤에 원본 Flux에서 숫자 5를 emit합니다. 이때 버퍼 오버플로가 발생해 5를 버퍼에 채우지 못하고 Drop되게 되는 것입니다. 그 뒤의 숫자 6 또한 마찬가지 입니다. 여전히 버퍼의 상태는 [ 4, 2 ] 입니다.
- 이제 버퍼에서 다시 숫자 2가 emit 됩니다. 이때 버퍼의 상태는 [ 4 ] 입니다.
- 그리고 원본 Flux에서 숫자 7을 emit해 버퍼에 채워집니다. 이때 버퍼의 상태는 [ 7, 4 ]입니다.
사진 왼쪽의 시간과 함께 비교하며 분석해본다면, 이해하기 훨씬 쉬울 것입니다.
BUFFER DROP_OLDEST 전략
BUFFER DROP_OLDEST 전략은
Publisher가 Downstream으로 전달할 데이터가 버퍼에 가득 찰 경우, 버퍼 안에 채워진 데이터 중에서 가장 오래된 데이터를 Drop하여 폐기한 후, 확보된 공간에 emit된 데이터를 채우는 전략
입니다. 앞서 본 DROP_LATEST와 정반대의 전략이라고 볼 수 있습니다.
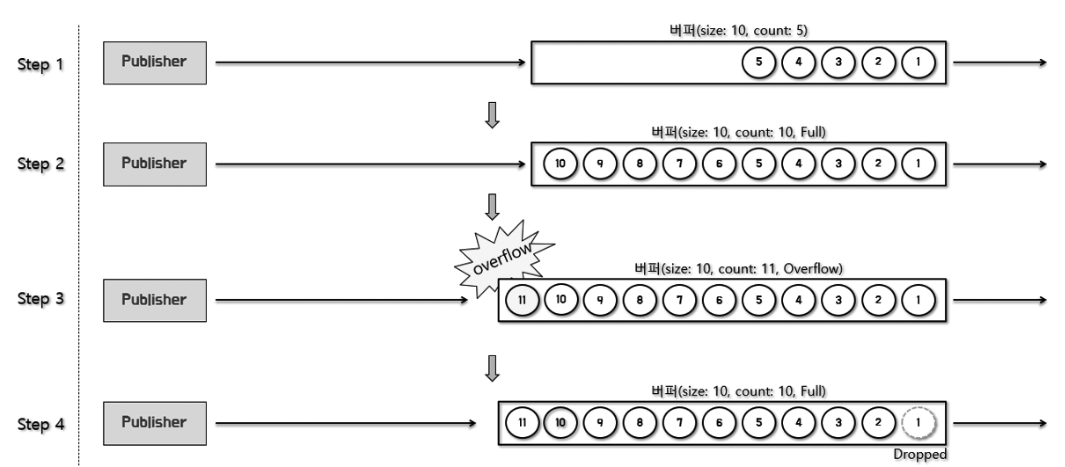
- Step 1, 2, 3는 앞선 상황과 같습니다.
- Step 4 := 여기서 숫자 11이 Drop 되는 것이 아니라 버퍼 제일 앞쪽에 있는(가장 오래된) 숫자 1이 Drop됩니다.
@Slf4j
public class DemoApplication {
static final Logger log = LoggerFactory.getLogger(DemoApplication.class);
public static void main(String[] args) throws InterruptedException {
Flux
.interval(Duration.ofMillis(300L))
.doOnNext(data -> log.info("# emitted by original Flux: {}", data))
.onBackpressureBuffer(2,
dropped -> log.info("** Overflow & Dropped: {} **", dropped),
BufferOverflowStrategy.DROP_OLDEST)
.doOnNext(data -> log.info(" [ # emitted by Buffer: {} ]", data))
.publishOn(Schedulers.parallel(), false, 1)
.subscribe(data -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) { }
log.info("# onNext: {}", data);
},
error -> {
log.error("# onError");
error.printStackTrace();
});
Thread.sleep(3000L);
}
}앞선 코드에서 BUFFER 전략 부분만 `DROP_OLDEST`로 변경한 코드입니다. 실행 결과는 다음과 같습니다.
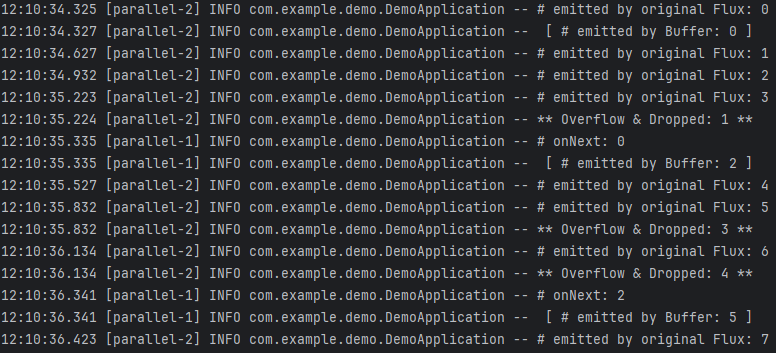
- 원본 Flux에서 숫자 0이 emit 되고, 버퍼에 잠시 채워진 다음 버퍼에서 다시 emit 됩니다. 이때 버퍼의 상태는 [ ]가 됩니다.
- 원본 Flux가 emit한 숫자 0을 Subscriber가 처리하기까지 1초 정도가 걸립니다.
- 숫자 0을 처리하는 1초 동안 원본 Flux에서는 0.3초에 한 번씩 숫자 1, 2를 emit합니다. 버퍼 최대 용량이 2이기 때문에 버퍼의 상태는 [ 2, 1 ] 이 됩니다.
- 그리고 원본 Flux에서 숫자 3을 emit하게 되는데, 버퍼 오버플로가 발생합니다. 이때, DROP_OLDEST 전략을 사용했기 때문에 버퍼 안에 있는 데이터 중 가장 오래된 데이터인 숫자 1이 Drop됩니다. 현재 버퍼의 상태는 [ 3, 2 ]입니다.
이후 과정은 생략하겠습니다. 앞의 LATEST와 비교하며 살펴보면 쉽게 이해할 수 있을겁니다.
참고
"스프링으로 시작하는 리액티브 프로그래밍"
'스프링(Spring) > WebFlux' 카테고리의 다른 글
| [Spring/WebFlux] Context (1) | 2024.02.29 |
|---|---|
| [Spring/WebFlux] Sinks (0) | 2024.02.22 |
| [Spring/WebFlux] Cold Sequence와 Hot Sequence (1) | 2024.02.20 |
| [Spring/WebFlux] 마블 다이어그램(Marble Diagram)으로 보는 Mono & Flux (0) | 2024.02.14 |
| [Spring/WebFlux] Reactor (0) | 2024.02.13 |