

Reactor에서 사용되는 Siganl을 프로그래밍 방식으로 전송할 수 있는 Sinks에 대해 알아봅시다.
Sinks란?
Sinks는 앞서 설명했던, Processor 인터페이스의 기능을 개선한 것입니다. Sinks에 대해 Reactor API 문서에서는 다음과 같이 설명하고 있습니다.

첫 문장을 보면, "Sinks는 리액티브 스트림즈의 Signal을 프로그래밍 방식으로 push 할 수 있는 구조이며, Flux or Mono의 의미 체계를 가진다" 라고 설명하고 있습니다.
지금까지 설명했던 방식은 모두 Flux 또는 Mono가 onNext 같은 Signal을 (메서드 체이닝을 이용해서)내부적으로 전송해주는 방식이었는데, Sinks를 사용하면 프로그래밍 코드를 통해 명시적으로 Signal을 전송할 수 있습니다.
하지만, Reactor에서 프로그래밍 방식으로 Signal을 전송하는 가장 일반적인 방법은 generate()나 create() 와 같은 Operator를 사용하는 것인데, 이는 Reactor에서 Sinks를 지원하기 전부터 이미 사용하던 방식입니다.
그럼 이 방식과 Sinks를 사용하는 것에는 어떤 차이점이 있을까요?
Operator 사용 방식 vs Sinks 사용 방식
Operator 사용 방식
일반적으로 generate()나 create() Operator는 싱글스레드 기반에서 Signal을 전송하는데 사용하지만, Sinks는 멀티스레드 방식으로 Signal을 전송해도 스레드 안전성을 보장하기 때문에 예기치 않은 동작으로 이어지는 것을 방지해줍니다.
각각의 마블 다이어그램과 설명은 다음과 같습니다.
generate( )
create( )
우선, create() Operator를 사용해 프로그래밍 방식으로 Signal을 전송하는 코드를 살펴봅시다.
@Slf4j
public class DemoApplication {
static final Logger log = LoggerFactory.getLogger(DemoApplication.class);
public static void main(String[] args) throws InterruptedException {
int tasks = 6;
Flux
.create((FluxSink<String> sink) -> {
IntStream
.range(1, tasks)
.forEach(n -> sink.next(doTask(n)));
})
.subscribeOn(Schedulers.boundedElastic())
.doOnNext(n -> log.info("# create() : {}", n))
.publishOn(Schedulers.parallel())
.map(result -> result + "success!!")
.doOnNext(n -> log.info("# map() : {}", n))
.publishOn(Schedulers.parallel())
.subscribe(data -> log.info("# onNext() : {}", data));
Thread.sleep(500L);
}
static String doTask(int taskNumber) {
// now tasking...
// complete to task.
return "Task " + taskNumber + " result";
}
}위 코드에서 create(), subscribeOn(), publishOn()과 같은 Operator에 대한 설명은 뒤에서 자세히 다루고 이번 포스팅에서 자세한 설명은 하지 않겠습니다.
위 코드는 총 5개의 어떤 작업을 수행한 후, 작업 수행 결과를 Subscriber에게 전달하는 시나리오를 구현한 코드입니다.
- 먼저
create()Operator가 처리해야 할 작업의 개수만큼doTask()메서드를 호출해서 작업을 처리한 후, 결과를 리턴받습니다. - 이 결과를
map()Operator를 사용해 추가적으로 가공 처리한 후에 최종적으로 Subscriber에게 전달합니다.
여기서, 작업 처리, 처리 결과 가공, 가공된 결과 제공의 각각의 단계를 (코드의 Schedulers.의 부분을 통해서) 모두 별도의 스레드에서 실행하도록 구성했습니다. 결과적으로 Reactor Sequence는 main 스레드를 제외하고 총 3개의 스레드가 동시에 실행됩니다.
실행 결과는 다음과 같습니다.
결과를 살펴보면, doTask() 메서드의 작업 처리는 boundedElastic-1 스레드에서, map()에서의 가공 처리는 parallel-2 스레드에서, Subscriber에서 전달받은 데이터 처리는 parallel-1 스레드에서 실행되는 것을 볼 수 있습니다.
이처럼 create() Operator를 사용해 프로그래밍 방식으로 Signal을 전송할 수 있고, Sequence를 단계적으로 나누어 여러 개의 스레드로 처리할 수 있습니다.
그런데, 다음과 같은 상황을 생각해봅시다.
위 코드에서 작업을 처리한 후, 그 결과 값을 반환하는 doTaks() 메서드가 싱글스레드가 아닌 여러 개의 스레드에서 각각의 "전혀 다른 작업들"을 처리한 후, 처리 결과를 반환하는 상황이라면?
현재는 한 개의 boundedElastic-1 스레드에서 doTask() 메서드가 실행되고 있는 것을 볼 수 있습니다.
이 같은 상황에서 적절히 사용할 수 있는 방식이 Sinks입니다.
Sinks 사용 방식
@Slf4j
public class DemoApplication {
static final Logger log = LoggerFactory.getLogger(DemoApplication.class);
public static void main(String[] args) throws InterruptedException {
int tasks = 6;
Sinks.Many<String> unicastSink = Sinks.many().unicast().onBackpressureBuffer();
Flux<String> fluxView = unicastSink.asFlux();
IntStream
.range(1, tasks)
.forEach(n -> {
try {
new Thread(() -> {
unicastSink.emitNext(doTask(n), Sinks.EmitFailureHandler.FAIL_FAST);
log.info("# emitted : {}", n);
}).start();
Thread.sleep(100L);
} catch (InterruptedException e) {
log.error(e.getMessage());
}
});
fluxView
.publishOn(Schedulers.parallel())
.map(result -> result + "success!!")
.doOnNext(n -> log.info("# map() : {}", n))
.publishOn(Schedulers.parallel())
.subscribe(data -> log.info("# onNext() : {}", data));
Thread.sleep(200L);
}
static String doTask(int taskNumber) {
// now tasking...
// complete to task.
return "Task " + taskNumber + " result";
}
}위의 코드는 앞선 코드와 달리 doTask() 메서드가 루프를 돌 때마다 새로운 스레드에서 실행됩니다. 그리고 doTask() 메서드의 작업 처리 결과를 Sinks를 통해서 Downstream에 emit 합니다.
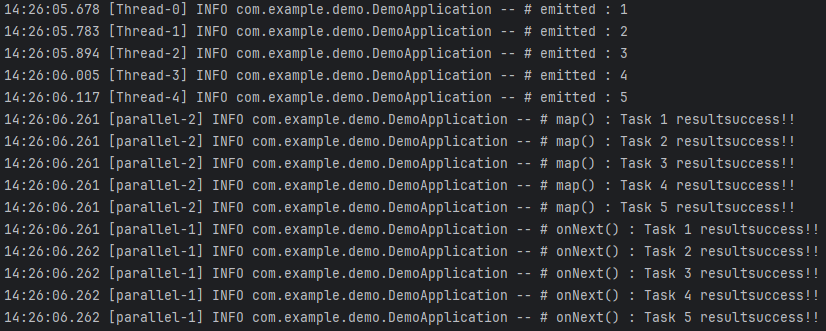
doTask() 메서드가 총 5개의 스레드에서 실행된 것을 확인할 수 있습니다. 결과적으로는 총 7개의 스레드가 실행되었습니다.
이처럼 Sinks는 프로그래밍 방식으로 Signal을 전송할 수 있으며, 멀티스레드 환경에서 스레드 안전성(Thread Safety)을 보장받을 수 있는 장점이 있습니다.
참고) 스레드 안전성( Thread Safety)
공유 자원에 동시 접근할 경우에도 프로그램의 실행에 문제가 없음을 의미합니다. 교착 상태(Dead Lock)에 빠지게 되면 스레드 안전성이 깨지게 됩니다.
Processor에서는 onNext, onComplete, onError 메서드를 "직접적으로" 호출함으로써 스레드 안전성이 보장되지 않을 수 있는데, Sinks의 경우에는 동시 접근을 감지하고, 동시 접근하는 스레드 중 하나가 빠르게 실패함으로써 스레드 안전성을 보장합니다.
Sinks 종류 및 특징
Reactor에서 Sinks를 사용해 Signal을 전송하는 방법은 크게 Sinks.One과 Sinks.Many 2가지 입니다.
Sinks.One( )
Sinks.One은
Sinks.One() 메서드를 사용해 한 건의 데이터를 전송하는 방법을 정의해 둔 기능 명세입니다.
Sinks.one( )의 메서드 내부는 다음과 같습니다.

Sinks.one() 메서드를 호출하는 것은 한 건의 데이터를 프로그래밍 방식으로 emit 하는 기능을 사용하고 싶어 이에 맞는 기능 명세를 달라고 요청하는 것과 같습니다.
@Slf4j
public class DemoApplication {
static final Logger log = LoggerFactory.getLogger(DemoApplication.class);
public static void main(String[] args) {
Sinks.One<String> sinkOne = Sinks.one();
Mono<String> mono = sinkOne.asMono();
sinkOne.emitValue("Hello Reactor!", Sinks.EmitFailureHandler.FAIL_FAST);
mono.subscribe(data -> log.info("# Subscriber A : {}", data));
mono.subscribe(data -> log.info("# Subscriber B : {}", data));
}
}Sinks.one() 메서드를 호출하면, Sinks.One 객체로 데이터를 emit 할 수 있습니다. Sinks.EmitFailureHandler.FAIL_FAST는 emit 도중에 에러가 발생할 경우 처리할 방법에 대한 Handler입니다.
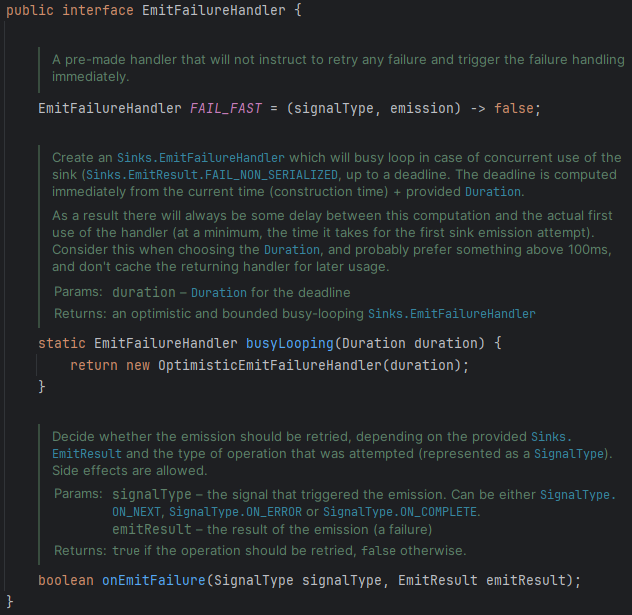
위 내용을 보면 Sinks 클래스 안에 정의된 EmitFailureHandler 인터페이스를 볼 수 있습니다. FAIL_FAST는 이 인퍼페이스의 구현 객체입니다. 이 객체를 통해 emit 도중 발생하는 에러에 대해 빠르게 실패 처리합니다. 즉, 에러가 발생했을 때 재시도를 하지 않고 즉시 실패 처리를 한다는 의미입니다. 스레드의 안전성을 보장하기 위한 작업입니다.
다시 코드로 돌아가면, emit 한 데이터를 구독하여 전달받기 위해 asMono() 메서드를 사용해 Mono 객체로 변환합니다.

이렇게 변환된 Mono 객체를 통해 emit 된 데이터를 전달받을 수 있습니다.
그리고, Sinks.One으로 아무리 많은 수의 데이터를 emit하더라도 처음 emit한 데이터는 정상적으로 emit되지만 나머지 데이터들은 Drop됩니다.
Sinks.Many
Sinks.Many는
Sinks.many() 메서드를 사용해서 여러 건의 데이터를 여러 가지 방식으로 전송하는 기능을 정의해 둔 기능 명세 라 볼 수 있습니다.

Sinks.many() 메서드의 경우, Sinks.Many를 리턴하는 것이 아닌 ManySpec이라는 인터페이스를 리턴하고 있는 것을 볼 수 있습니다.
Sinks.One은 단순히 한 건의 데이터를 emit 하는 한 가지 기능만 가지기 때문에 별도의 Spec이 정의되지 않고 Default Spec을 사용합니다. 하지만, Sinks.Many의 경우, 데이터 emit을 위한 여러 가지 기능이 정의된 ManySpec을 리턴합니다.

ManySpec 인터페이스는 총 세 가지 기능(unicast(), multicast(), replay())을 정의하는데, 이 세 기능은 각각의 기능을 또다시 별도의 Spec(UnicastSpec, MulticastSpec, MulticastReplaySpec)으로 정의해 두고 있습니다.
하나씩 살펴 봅시다.
unicast( ) - UnicastSpec
@Slf4j
public class DemoApplication {
static final Logger log = LoggerFactory.getLogger(DemoApplication.class);
public static void main(String[] args) {
Sinks.Many<Integer> unicastSink = Sinks.many().unicast().onBackpressureBuffer();
Flux<Integer> fluxView = unicastSink.asFlux();
unicastSink.emitNext(1, Sinks.EmitFailureHandler.FAIL_FAST);
unicastSink.emitNext(2, Sinks.EmitFailureHandler.FAIL_FAST);
fluxView.subscribe(data -> log.info("# Subscribe A : {}", data));
unicastSink.emitNext(3, Sinks.EmitFailureHandler.FAIL_FAST);
// fluxView.subscribe(data -> log.info("# Subscribe B : {}", data));
}
}위 코드에서는 ManySpec의 구현 메서드인 unicast() 메서드를 호출했습니다. 이를 호출하면 리턴 값으로 UnicastSpec을 리턴하고 이에 정의된 기능을 사용합니다. 그리고, asFlux() 메서드를 사용해 Flux 객체로 변환합니다.
실행 결과는 다음과 같습니다.

그런데 만약, 마지막 라인의 코드의 주석을 해제하고 실행한다면 어떤 결과가 나올까요?
UnicastSpec의 기능이 단 하나의 Subscriber에게만 데이터를 emit하는 것이기 때문에 두 번째 Subscriber에게 전달되지 않든가 에러가 발생하든가 할 것입니다.

unicast() sinks는 단일 Subscriber에게만 허용된다고 친절하게 설명까지 해주네요.
multicast( ) - MulticastSpec
다음으로 multicast()를 사용하는 코드를 살펴 봅시다.
@Slf4j
public class DemoApplication {
static final Logger log = LoggerFactory.getLogger(DemoApplication.class);
public static void main(String[] args) {
Sinks.Many<Integer> multicastSink = Sinks.many().multicast().onBackpressureBuffer();
Flux<Integer> fluxView = multicastSink.asFlux();
multicastSink.emitNext(1, Sinks.EmitFailureHandler.FAIL_FAST);
multicastSink.emitNext(2, Sinks.EmitFailureHandler.FAIL_FAST);
fluxView.subscribe(data -> log.info("# Subscribe A : {}", data));
fluxView.subscribe(data -> log.info("# Subscribe B : {}", data));
multicastSink.emitNext(3, Sinks.EmitFailureHandler.FAIL_FAST);
}
}이번에는 ManySpec의 구현 메서드 중 multicast() 메서드를 호출했습니다. 이를 호출하면 리턴 값으로 MulticastSpec을 리턴합니다.
MulticastSpec의 기능은 하나 이상의 Subscriber에게 데이터를 emit 하는 것입니다.
실행 결과는 다음과 같습니다.

Sinks가 Publisher의 역할을 할 경우 기본적으로 Hot Publisher로 동작합니다. 또한, onBackpressureBuffer() 메서드는 Warm up(최초 구독이 발생하기 전까지 데이터의 emit이 발생하지 않는 것)의 특징을 가지는 Hot Sequence로 동작하기 때문에 Subscriber B는 일부 데이터를 받을 수 없습니다.
replay( ) - MulticastReplaySpec
마지막으로 replay() 메서드를 호출하는 코드입니다.
@Slf4j
public class DemoApplication {
static final Logger log = LoggerFactory.getLogger(DemoApplication.class);
public static void main(String[] args) {
Sinks.Many<Integer> replaySink = Sinks.many().replay().limit(2);
Flux<Integer> fluxView = replaySink.asFlux();
replaySink.emitNext(1, Sinks.EmitFailureHandler.FAIL_FAST);
replaySink.emitNext(2, Sinks.EmitFailureHandler.FAIL_FAST);
replaySink.emitNext(3, Sinks.EmitFailureHandler.FAIL_FAST);
fluxView.subscribe(data -> log.info("# Subscribe A : {}", data));
replaySink.emitNext(4, Sinks.EmitFailureHandler.FAIL_FAST);
fluxView.subscribe(data -> log.info("# Subscribe B : {}", data));
}
}replay() 메서드를 호출하면 리턴 값으로 MulticastReplaySpec을 리턴하고 이의 구현 메서드 중 하나인 limit() 메서드를 호출합니다.
MulticastReplaySpec에는 emit 된 데이터를 다시 replay 해서 구독 전에 이미 emit 된 데이터라도 Subscriber가 전달 받을 수 있게 하는 다양한 메서드들이 정의되어 있습니다.
대표적으로 다음 2개의 메서드가 존재합니다.
all():= 구독 전에 이미 emit 된 데이터가 있더라도 처음 emit 된 데이터부터 모든 데이터들이 Subscriber에게 전달limit():= emit 된 데이터 중에서 파라미터로 입력한 개수만큼 가장 나중에 emit 된 데이터부터 Subscriber에게 전달
위 코드의 실행 결과는 다음과 같습니다.

첫 번째 Subscriber의 입장에서는 구독 시점에 이미 세 개의 데이터가 emit 되었기 때문에 마지막 2개인 2, 3을 전달 받습니다. 두 번째 Subscriber의 경우, 구독 전에 숫자 4의 데이터가 한 번 더 emit 되었기 때문에 구독 시점에 마지막 2개를 뒤로 돌린 숫자 3, 4를 받게 됩니다.
참고
"스프링으로 시작하는 리액티브 프로그래밍"
'스프링(Spring) > WebFlux' 카테고리의 다른 글
| [Spring/WebFlux] Debugging (0) | 2024.03.14 |
|---|---|
| [Spring/WebFlux] Context (1) | 2024.02.29 |
| [Spring/WebFlux] Backpressure (0) | 2024.02.20 |
| [Spring/WebFlux] Cold Sequence와 Hot Sequence (1) | 2024.02.20 |
| [Spring/WebFlux] 마블 다이어그램(Marble Diagram)으로 보는 Mono & Flux (0) | 2024.02.14 |