

데이터베이스 설계란, 조직체의 운영 및 목표 달성을 위해 데이터베이스를 생성하는 일련의 과정이다. 기본적으로 정보 시스템 개발 절차를 따른다. 아래 그림은 데이터베이스 개발의 생명 주기(Life cycle)를 보여주고 있다.

이러한 DB 개발 과정에는 요구사항 분석, 설계, 구현, 운영, 감시 및 개선으로 나누어 볼 수 있다.
유의할 사항은 생명 주기의 어떤 단계에서 문제가 발생하면 그 피드백을 받아 그 앞의 적절한 단계로 되돌아가 그 단계부터 다시 계속된다는 것이다.
이 중에서 "설계" 단계에 중점을 두고 알아보자.
데이터베이스 설계 단계에는 다음과 같이 5단계로 구분하고 있다.
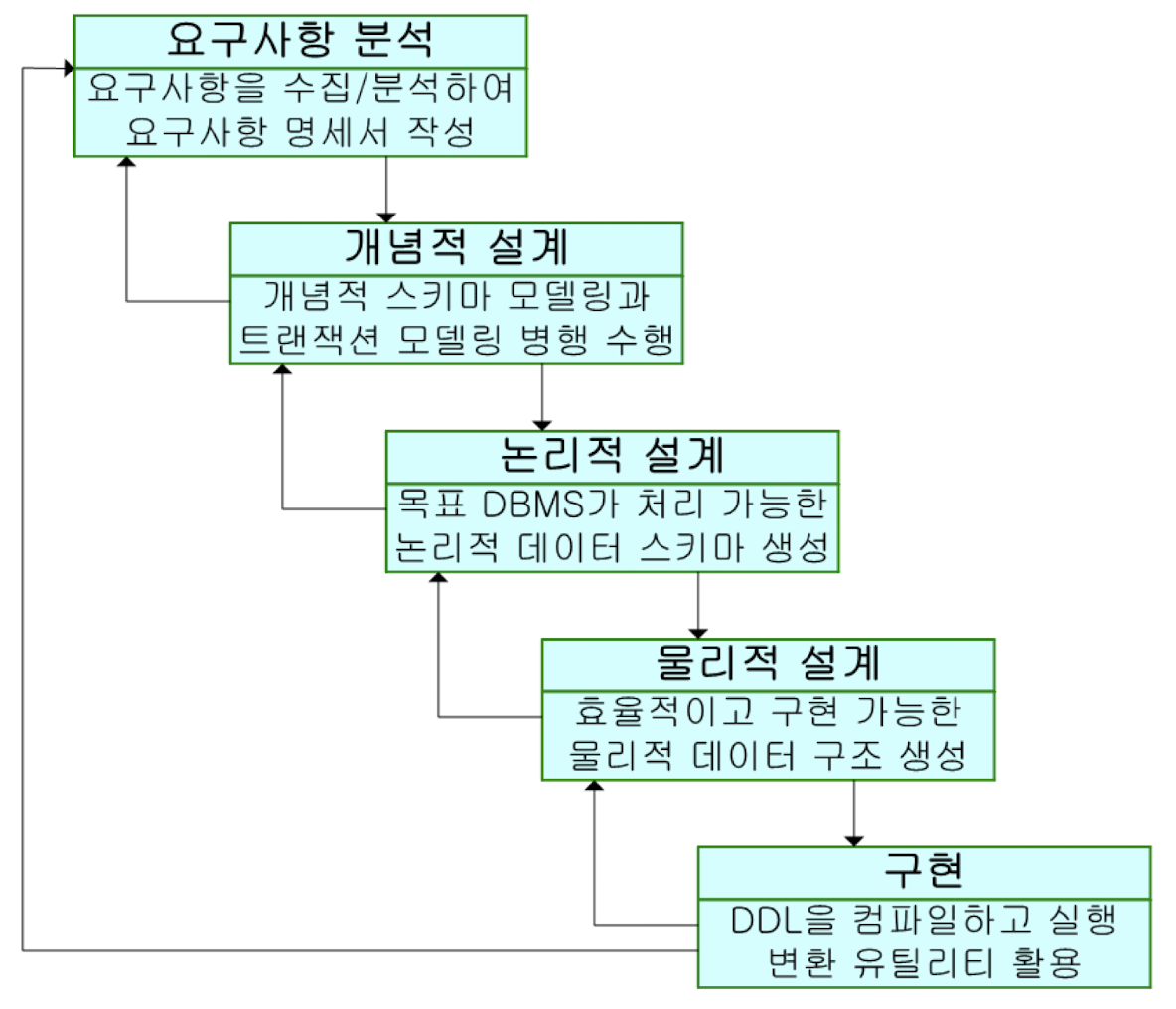
데이터베이스 설계 단계는 데이터베이스 개발 과정 중에서 요구사항 분석을 기초로 하여 데이터베이스 구조를 작성하는 과정이다.
🏷 데이터베이스 설계 시 고려 사항
- 무결성(Integrity) : DB에 대한 변경 연산(갱신, 삽입, 삭제)이 수행된 뒤에도 데이터 값이 만족해야 될 주어진 제약 조건을 항상 만족해야 한다.
- 일관성(Consistency) : 저장된 두 데이터 값 사이나 특정 질의에 대한 응답 간에 모순성 없이 일치해야 한다.
- 회복(Recovery) : 시스템에 장애가 발생했을 때 장애 발생 이전의 일관된 상태로 복수할 수 있는 능력을 말한다.
- 보안(Security) : 권한이 없는 사람이 의도적, 불법적으로 데이터를 변경, 손실, 노출시키는 것을 방지하는 것을 말한다.
- 효율성(Efficiency) : 응답 시간 단축, 저장 공간 최적화, 시스템 생산성 향상 등이 포함된다.
- 확장성(Extensibility) : 시스템 운영에 영향을 주지 않으면서 새로운 데이터를 계속적으로 추가시켜 나갈 수 있는 기법을 가져야 한다.
📂 요구사항 분석
요구사항 분석(Requirement analysis) 단계에서는 사용자의 요구사항을 수집하고 분석하여 공식적인 요구사항 명세서(Requirement Specification)를 생성하는 것이 주요 과제다. 실제로 전체 시스템 개발 과정 중에서 가장 어려운 단계이다.
요구사항 명세서에는 다음과 같은 내용들이 포함되어야 한다.
- 개체, 애트리뷰트, 관계성, 제약 조건 등과 같은 정적 정보 구조에 대한 요구사항
- 트랜잭션 유형, 트랜잭션 실행 빈도와 같은 동적 데이터베이스 처리 요구사항
- 회사의 경영 목표 및 정책, 그리고 규정과 같은 범 기관적 제약 조건
자료의 수집과 분석 등을 거치고 나면 많은 분량의 문서들이 쌓이게 되는데, 이 자료들의 정리와 분석을 통해 업무를 개념화, 도식화하는 데에 소프트웨어 공학 기법들이 사용되기도 한다. 이러한 기법들의 예로 HIPO(Hierarchical Input Process Output), SADT(Structured Analysis and Design Technique), DFD(Data flow Diagram), Orr-Warnier 다이어그램 ... 등이 있다.
이 중 DFD에 대해서 좀 더 자세히 알아보자.
DFD는 시스템 내에서 데이터가 어떻게 생성되어 어떤 프로세스를 거쳐 어디로 저장되는지를 가시적으로 보여준다. DFD는 약속된 표기법에 따라 작성을 하게 되는데 사용하는 요소와 의미는 다음과 같다.

📂 개념적 설계
요구사항 분석 단계가 끝나면 개념적 설계(Conceptual design) 단계가 시작된다. 요구사항 명세서로부터 개념적 데이터 스키마가 만들어진다. 이러한 개념적 데이터 스키마는 다음 단계인 논리적 설계 단계의 입력으로 사용된다.
개념적 설계 단계에서는 개념적 스키마 모델링과 트랜잭션 모델링 두 가지 활동을 병행적으로 수행하게 된다.
📄 개념적 스키마 모델링(Conceptual schema modeling)
개념적 스키마 모델링에서는 DBMS에 독립적인 표현 기법인 E-R 다이어그램을 사용한다. 즉, 요구사항 분석 결과로 나온 명세서를 E-R 다이어그램과 같은 개념적 데이터 모델(Conceptual data model)로 기술한다. 이러한 과정을 개념적 데이터 모델링이라 하고, 이 결과를 개념적 데이터 구조 or 개념적 데이터 스키마라고 한다.
개념적 데이터 스키마를 모델링하기 위해서 먼저 스키마의 구성 요소가 되는 개체(Entity), 속성(Attribute), 관계(Relation)를 식별해서 결정해야 한다. 개념적 데이터 스키마를 유도하는 기본 원리는 추상화(Abstraction)이다. 추상화는 복잡한 현실 세계를 쉽게 이해하기 위해 현실 세계를 단순화, 개념화시켜 표현한 것을 말한다. 이러한 추상화 방법에는 집단화와 일반화가 있다.
- 집단화(Aggregation) : 하위 클래스의 몇 개의 속성을 묶어서 하나의 새로운 개체를 생성하는 것이다.
- 일반화(Generalization) : 하위 레벨 개체 집합의 공통적인 특성을 파악하여 더 상위 레벨의 개체를 생성하는 것이다.
다음 그림은 집단화와 일반화의 예시이다.

📄 트랜잭션 모델링(Transaction modeling)
트랜잭션 모델링은 요구사항 분석 단계에서 얻어진 결과를 검토해서 이들에 대한 트랜잭션들을 명세서에 기술하는 과정이다. 응용을 위한 데이터 처리에 중점을 두기 때문에 처리 중심 설계라 하며, 주요 트랜잭션들을 식별하고 이들에 대한 기능적 특성을 DB 설계 초기 단계에 명세해 놓는 것이다.
이렇게 하면 데이터베이스 스키마에 트랜잭션이 필요로 하는 정보가 모두 포함되어 있는지 확인할 수 있다. 또한, 트랜잭션들 사이의 상대적 중요성과 예상 실행 빈도수를 파악해 물리적 DB를 설계할 때도 중요한 정보로 사용될 수 있다.
개념적 설계 단계에서 트랜잭션 모델링은 트랜잭션 입출력(I/O)과 기능적 형태만 주로 정의한다. 즉, 입력 데이터, 출력 데이터, 내부적인 제어 흐름을 기술한다.
트랜잭션 모델링의 한 예로는 다음과 같은 것이 있다.
📂 논리적 설계
논리적 설계(Logical design) 단계는 개념적 설계에서 생성된 개념적 데이터 스키마로부터 목표 DBMS가 처리할 수 있는 논리적 데이터 스키마를 설계하는 단계이다. 이 스키마는 요구사항 명세서를 만족해야 하고 무결성, 일관성, 제약 조건도 만족해야 한다.
가장 많이 사용되는 논리적 데이터 모델은 관계형 데이터 모델이지만, 논리적 설계는 다음과 같이 논리적 데이터 모델로 변환, 트랜잭션 인터페이스 설계, 스키마의 평가 및 정제 이 3단계를 거쳐 수행된다.
📄 논리적 데이터 모델 변환
먼저 개념적 설계 단계에서 생성된 개념적 데이터 스키마를 목표 DBMS에 맞는 스키마, 즉 논리적 데이터 모델로 변환한다. 이 변환 과정을 논리적 데이터 모델링이라 하며, 여기서 사용되는 데이터 모델로 관계형 데이터 모델이 있다. 이 단계에서 생성된 결과는 목표 DBMS의 데이터 정의어(DDL)로 기술된 스키마가 된다. 하지만 이 DDL 명령문에는 물리적 설계 단계에서 결정해야 될 매개변수들이 포함될 수 있어 완전한 스키마 정의는 물리적 설계 단계까지 보류하는 것이 일반적이다.
📄 트랜잭션 인터페이스 설계
논리적 설계의 두 번째 단계는 트랜잭션의 인터페이스를 설계한다. 완전하고 세부적인 트랜잭션을 설계하는 것이 아니라, 트랜잭션(예를 들어, Stored Procedure)의 전체적인 골격을 개발하고 인터페이스를 정의하는 것이다. 또한 각 트랜잭션에 대한 데이터 접근 방법을 기술한다.
📄 스키마 평가 및 정제
논리적 설계의 세 번째 단계는 설계된 스키마를 평가하고 정제하는 것이다. 데이터의 크기, 처리 빈도, 작업량 등과 같은 정량적 정보가 성능을 추정하기 위한 근거 자료로 사용된다.
관계형 데이터 모델 설계 예시를 하나 살펴보자.
아래는 학사 데이터베이스를 위한 E-R 다이어그램(개념적 설계 결과)이다.

이 다이어그램으로부터 관계형 데이터 모델로 변환하는 방법은 개략적으로 다음과 같다.
- 사각형으로 표시된 개체 타입은 하나의 릴레이션, 즉 개체 릴레이션으로 만든다.
- 다이아몬드로 표시된 관계(relationship)는 연관된 개체 타입의 키를 포함하는 관계 릴레이션으로 표현한다.
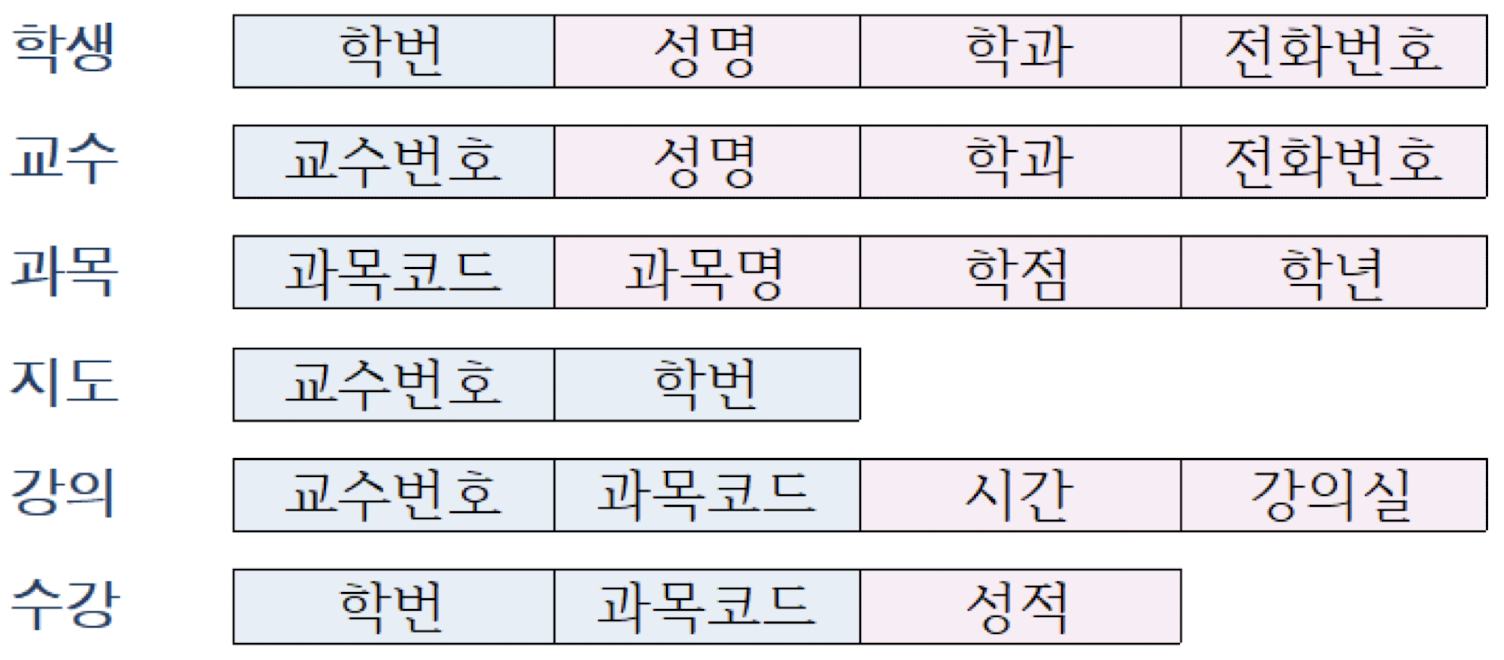
위는 관계를 독립된 릴레이션으로 표현한 결과이다. 관계 릴레이션인 지도 릴레이션을 확인해보면, 학생 개체 릴레이션과 교수 개체 릴레이션의 키(교수번호, 학번)를 포함하고 있는 것을 확인할 수 있다.
하지만, 이렇게 독립되게 표현하면 너무 많은 릴레이션이 만들어질 경향이 있다. 다른 변환 방법으로 관계를 맺고 있는 두 릴레이션에 공통되는 애트리뷰트(키)를 공통으로 갖게 함으로써 관계를 나타낼 수 있다. 이렇게 하면 릴레이션의 개수를 줄일 수 있고, 더 간편한 조작 방법을 제공할 수 있다.

(a)의 경우, 학생 릴레이션에 '교수번호'를 첨가시켰고, (b)의 경우 교수 릴레이션에 '학번'을 첨가시켰다.
둘 중 어느 것을 선택할 것인가는 설계자의 선택이다. 여기서 특별히 고려해야 할 사항은 데이터 중복과 데이터 처리의 효율성이다.
1:N인 경우, N쪽의 릴레이션에 공통되는 애트리뷰트(키)를 첨가시키는 것이 더 효율적이다.
위의 예시에서는 (a)의 경우가 더 효율적일 수 있다.
📂 물리적 설계
물리적 설계(Physical design)는 논리적 설계 단계에서 생성된 논리적 데이터 스키마로부터 효율적인 내부 스키마, 즉 물리적 데이터 구조를 설계하는 것이다. 물리적 데이터 구조는 데이터베이스 시스템의 성능에 중대한 영향을 미치므로 특히 효율성이 강조된다. 또한, 이 단계에서 트랜잭션의 상세 설계도 병행하여 수행된다.
물리적 데이터 구조의 기본적인 데이터 단위는 저장 레코드(Stored record)이다. 따라서 하나의 파일(File)은 한 타입의 저장 레코드들의 집합이 된다(하지만, 물리적 데이터 구조는 여러 가지 타입의 저장 레코드들의 집합이기 때문에 단순한 파일과는 전혀 다른 개념이다).
물리적 설계 단계에서는 다음과 같은 설계들을 포함한다.
📄 저장 레코드 양식(Stored record format)
저장 레코드의 양식(format) 설계 시 고려해야 할 사항으로는 데이터 타입, 데이터 값의 분포, 사용될 응용, 접근 빈도 등이 있다. 여기에는 저장 레코드에 대한 데이터 표현과 압축에 관한 정보도 포함된다. 또한 데이터의 접근 빈도수에 따라 그룹을 달리해 물리적으로 상이하게 저장하는 것도 포함시켜야 한다.
📄 레코드 집중화(Record clustering)
레코드 집중화란, 논리적으로 관련이 깊은 레코드들을 디스크 내에서 물리적으로 근접하도록 저장함으로써 물리적 순차성을 이용할 수 있게 하는 것을 말한다. 이 방법은 연속된 레코드의 검색을 요구할 때 레코드의 빠른 접근이 가능하다.
이때 효율적인 검색을 위해 블록의 크기의 선정이 중요하다. 순차 처리를 위주로 할 때는 블록의 크기를 크게 하는 것이 유리하고, 임의 접근 처리를 위주로 할 때에는 블록의 크기를 작게 하는 것이 유리하다.
📄 접근 경로(Access path)
접근 경로는 물리적 저장장치 위에 저장된 데이터의 검색과 저장을 가능하게 하는데, 저장 구조와 탐색 기법이 기본 요소가 된다. 저장 구조는 주로 인덱스를 통한 접근 방법과 데이터 파일을 정의하는 것이고, 탐색 기법은 주어진 응용을 위해 취해야 될 적절한 접근 경로를 정의하는 것이다.
접근 경로 설계는 다음 두 가지로 나누어 볼 수 있다.
- 기본 접근 경로(Primary access path)
- 기본키를 기본으로 한 기본 인덱스를 이용하는 것
- 초기 레코드 적재, 레코드의 물리적 위치, 기본키를 통한 검색과 밀접한 관계를 가진다.
- 주요 응용들이 이 기본 접근 경로를 이용해서 가장 효율적으로 처리될 수 있도록 설계
- 보조 접근 경로(Secondary access path)
- 보조키에 기반을 둔 보조 인덱스를 통해 저장 레코드를 접근하고 파일 간의 연결을 가능하게 한다.
- 접근 시간을 줄일 수 있다.
- 저장 공간을 추가로 사용해야 하고, 인덱스 관리가 복잡해진다.
물리적 데이터 구조를 설계할 때는 일반적으로 다음과 같은 사항을 고려해야 한다.
- 트랜잭션 응답 시간 : 트랜잭션 실행을 위해 시스템에 요구한 시점부터 결과를 받을 때까지 걸리는 시간
- 저장 공간의 효율화 : 파일이나 접근 경로를 저장하기 위해 필요한 최소한의 저장 공간
- 트랜잭션 처리도(throughput) : 단위 시간에 DBMS가 처리할 수 있는 평균 트랜잭션 수
📂 구현
물리적 설계가 끝나면 데이터베이스 구현 단계가 시작된다. 이 단계에서는 목표 DBMS의 DDL로 기술된 명령문이 데이터베이스 스키마와 빈 데이터베이스 파일을 생성하기 위해 컴파일되고 실행된다. 이때 데이터베이스에 데이터를 적재(Loading)시킨다.
데이터베이스의 트랜잭션은 응용 프로그래머에 의해 구현된다. 트랜잭션이 모두 작성되고 실제 데이터가 데이터베이스에 적재되면 데이터베이스의 설계 및 구현은 끝나게 되고 데이터베이스의 운영 단계로 넘어가게 된다.
위의 모든 데이터베이스 설계 과정을 단계별 입출력을 중심으로 요약하면 다음과 같다.

'데이터베이스' 카테고리의 다른 글
| [데이터베이스] 회복 (0) | 2022.12.03 |
|---|---|
| [데이터베이스] 무결성, 보안 (0) | 2022.12.03 |
| [데이터베이스] 데이터베이스 정규화 (2) | 2022.11.29 |
| [데이터베이스] SQL - 2 (0) | 2022.11.27 |
| [데이터베이스] SQL(Structured Query Language) - 1 (0) | 2022.11.26 |