

이제 CUDA를 이용해 대규모 벡터를 더해보자.
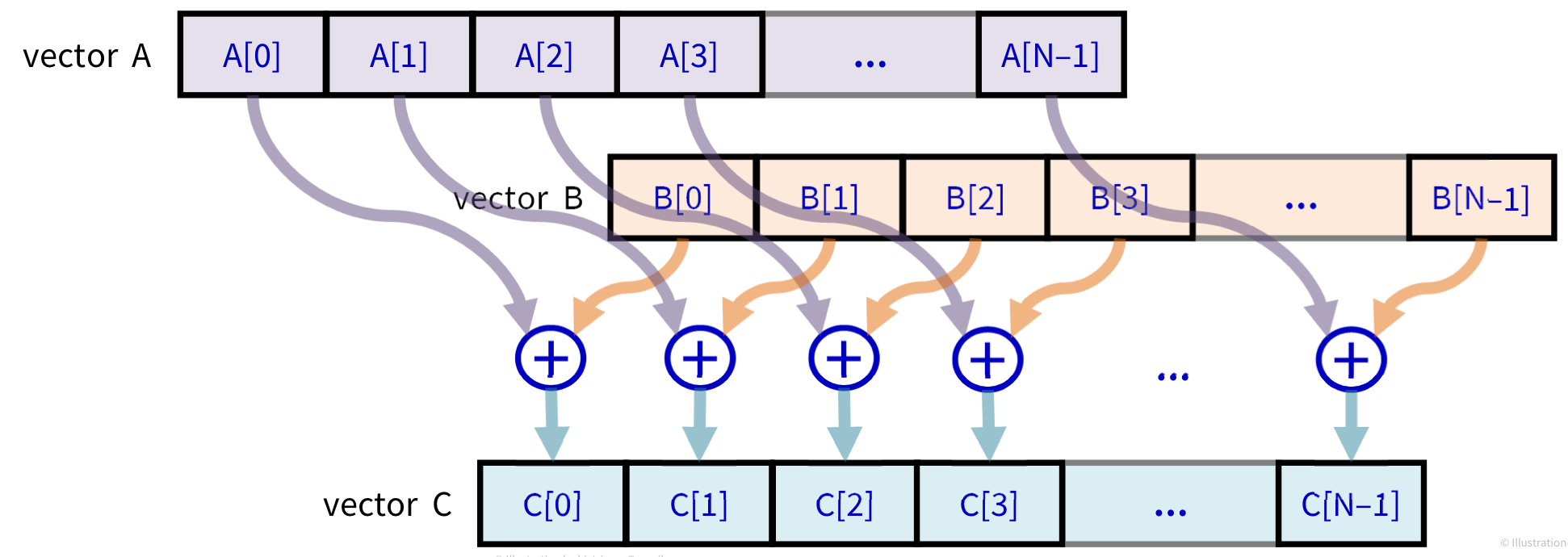
앞에서 계속 봐왔던 로직이지만, 이제 N의 개수가 256M개에서 많게는 1G개로 늘어난 배열에 대한 계산을 수행할 것이다.
📂 giga-add-host.cpp
먼저, host(CPU)에서 for-loop를 이용해 실행한 코드와 결과를 확인해보자. SIZE가 256MB인 경우이다.
코드
#include "./common.cpp"
const unsigned SIZE = 256*1024*1024; // big-size elements
int main(void){
...
//kernel: vector addition
ELAPSED_TIME_BEGIN(0);
for(register unsigned i=0;i<SIZE;++i){
vecC[i] = vecA[i] + vecB[i];
}
ELAPSED_TIME_END(0);
...
}결과
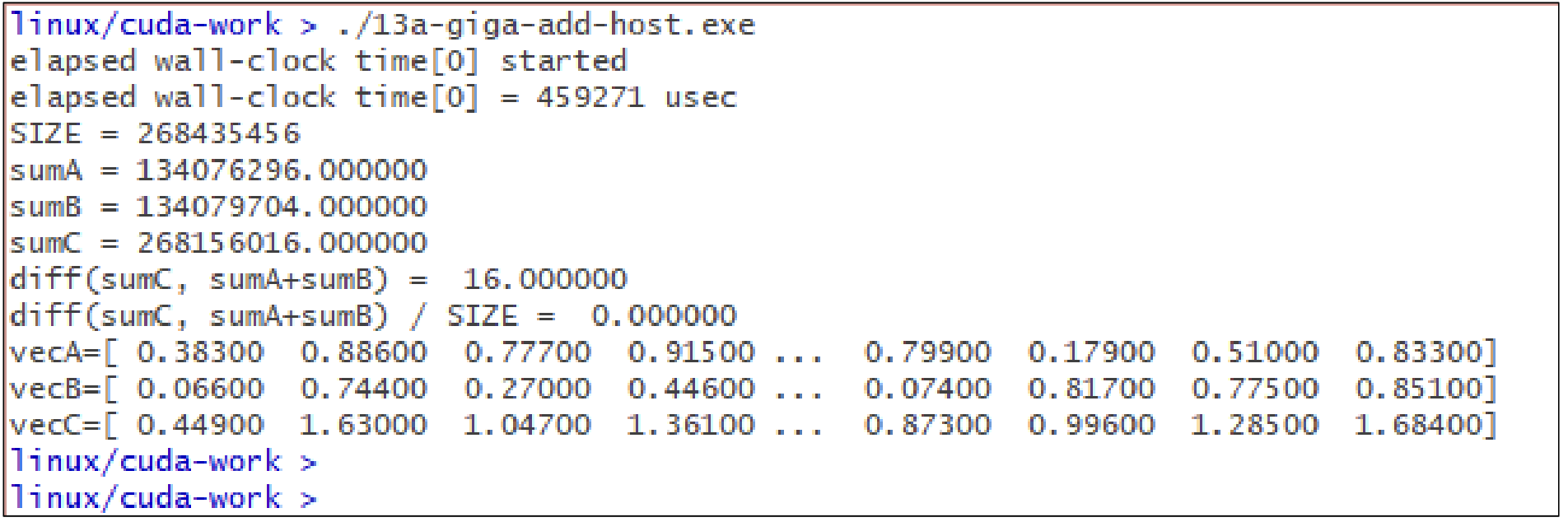
약 0.46초가 걸린 것을 확인할 수 있다.
📂 giga-add-single.cu
다음은 CUDA에서 single core를 사용한 경우의 코드와 결과이다.
코드
__global__ void singleKernelVecAdd(float* c, const float* a, const float* b){
for(register unsigned i=0;i<SIZE;++i){
c[i] = a[i] + b[i];
}
}
int main(void){
...
ELAPSED_TIME_BEGIN(0);
singleKernelVecAdd<<<1, 1>>>(dev_vecC, dev_vecA, dev_vecB);
cudaDeviceSynchronize();
ELAPSED_TIME_END(0);
CUDA_CHECK_ERROR();
...
}결과
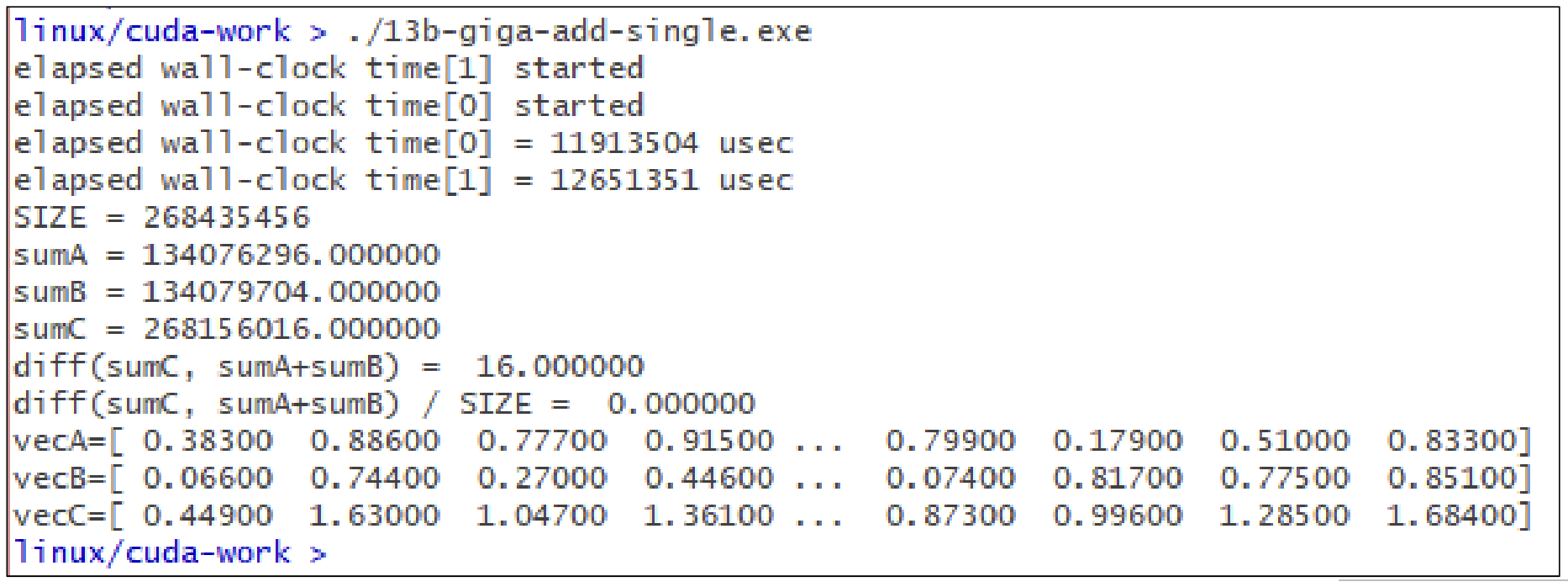
약 11초 가량 걸린 것을 확인할 수 있다.
📂 giga-add-dev.cu
이제 여러 thread를 이용하는 CUDA 병렬 처리 코드를 작성해보자.
__global__ void kernelVecAdd(float* c, const float* a, const float* b, unsigned n){
unsigned i = blockIdx.x * blockDim.x + threadIdx.x;
if(i<n){
c[i] = a[i]+b[i];
}
}이전 포스팅에서도 설명했지만, if(i<n)이 있는 이유는
blockDim과 vector size가 맞아 떨어진다는 보장이 없다.
예를 들어, vector size = 999인 경우이다. block은 32의 배수로 실행되기 때문에 딱 맞아 떨어지지 않는다.
dimGrid와 dimBlock을 계산해보자.
전체 thread의 개수는 dimBlock.x * dimGrid.x로 계산되는데, 이는 반드시 SIZE보다 큰 것을 보장해야한다. 즉,
$dimBlock.x * dimGrid.x >= SIZE$가 된다.
그렇기 때문에, dimGrid.x = ⌈SIZE/dimBlock.x ⌉(올림)으로 설정한다.
int main(void){
...
ELAPSED_TIME_BEGIN(0);
dim3 dimBlock(1024, 1, 1);
dim3 dimGrid( (SIZE+dimBlock.x-1)/dimBlock.x, 1, 1 );// 올림 연산
kernelVecAdd<<<dimGrid, dimBlock>>>(dev_vecC, dev_vecA, dev_vecB, SIZE);
cudaDeviceSynchronize();
ELAPSED_TIME_END(0);
...
}앞으로는 저렇게 dimBlock, dimGrid 변수를 넣을 것이다. Block dimension은 CUDA에서 거의 기계적으로 1024개 보다는 적게 사용해야된다고 되어 있어, 효율성을 위해 1024개를 사용한다. dimGird 변수는 공식처럼 사용되니 외워두자!
다음은 실행 결과이다.
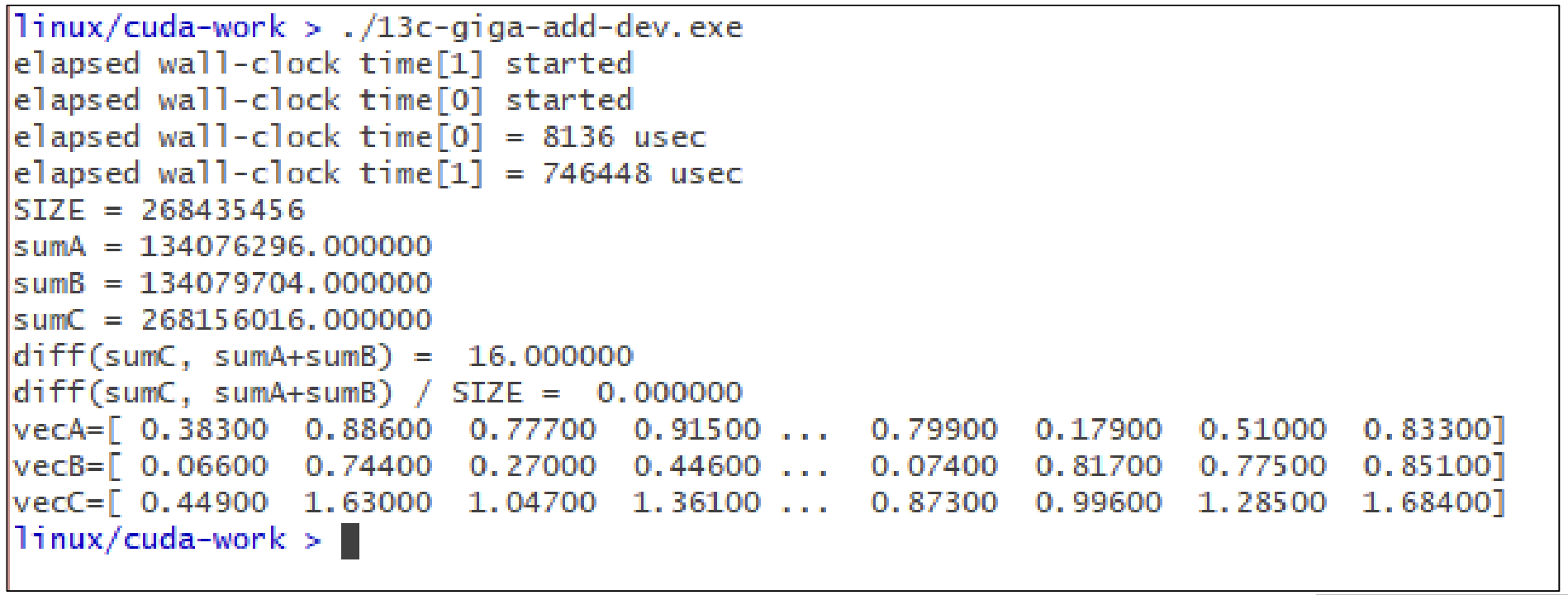
8136µsec가 걸린 것은 확인할 수 있다.
📂 clock() in the Kernel Function
clock_t clock(void);는 C/C++의 CPU 쪽에서 사용하는게 일반적이었지만, 이를 CUDA Kernel에서 사용할 수 있도록 추가적으로 구현한 것이다.
long long int clock64(void);이 함수가 CUDA Kernel 내에서 사용할 수 있는 버전이다. GPU에서 clock tick이 얼마나 되었는지 알려주는 함수이다. 주의할 점은 __device__, __global__함수에서 사용된다는 것이다.
다음과 같이 사용될 수 있다.
__global__ void kernelVecAdd(float* c, const float* a, const float* b, long long* times){
clock_t start = clock();
unsigned i = blockIdx.x * blockDim.x + threadIdx.x;
...
clock_t end = clock();
times[i] = (long long)(end - start);
}main 함수에 결과 값을 알려주기 위해 별도의 times배열을 추가해 사용했다.
이 clock 함수는 클럭 수행 횟수를 알려주는, 이 클럭 수행 횟수만으로는 실제 수행시간을 알 수가 없다. 수행 시간을 알기 위해서는 clock을 수행하는데 필요한 Hz를 알아야한다. 이때 사용하는 함수가 cudaDeviceGetAttribute() 함수이다.
📄 cudaDeviceGetAttribute()
cudaError_t cudaDeviceGetAttribute(int* value, cudaDeviceAttr attr, int device)value에 얻고자 하는 값이 들어간다. 여기서는 attr에 cudaDevAttrClockRate를 넣어 이 값을 알고 싶다고 전달해주는 것이다. device는 그래픽카드가 여러 개 있을때 지정해주는 것인데 우리는 하나의 그래픽카드만 가지고하기 때문에 0을 넣어주면 된다.
int clk_freq = 1;
cudaDeviceGetAttribute(&clk_freq, cudaDevAttrClockRate, 0);
float elapsed_usec = clk_ticks * 1000.0F / clk_freq;clk_ticks는 위에서 구한 times 배열에 있는 클럭 수행 횟수이다. 저 결과를 계산하는 수식은 외우자...
clk_ticks은 clock tick의 수이고 scalar(정수)값이다.
clk_freq는 clock frequency로, kHz단위이다.
📂 giga-add-clock.cu
이제 clock을 이용하여 clock의 개수, CUDA 안에서의 clock rate, thread 1개가 kernel을 실행하는 시간을 측정하는 코드를 작성해보자.
// CUDA kernel function
__global__ void kernelVecAdd(float* c, const float* a, const float* b, unsigned n, long long* times){
clock_t start = clock();
unsigned i = blockIdx.x * blockDim.x + threadIdx.x;
if(i<n){
c[i] = a[i] + b[i];
}
clock_t end = clock();
if(i==0){ // 0번 째 Thread에 대해서만 계산
times[0] = (long long)(end - start);
}
}
int main(void){
...
long long* dev_times = nullptr;
cudaMalloc((void**)&dev_times, 1*sizeof(long long));
...
//CUDA kernel Call
ELAPSED_TIME_BEGIN(0);
dim3 dimBlock(1024, 1, 1);
dim3 dimGrid( (SIZE + dimBlock.x - 1)/dimBlock.x, 1, 1);
kernelVecAdd<<<dimGrid, dimBlock>>>(dev_vecC, dev_vecA, dev_vecB, SIZE, dev_times);
cudaDeviceSynchronize();
ELAPSED_TIME_END(0);
CUDA_CHECK_ERROR();
...
//kernel clock calculation
int peak_clk = 1;
cudaDeviceGetAttribute(&peak_clk, cudaDevAttrClockRate, 0);
printf("num clock = %lld, peak clock rate = %dkHz, elapsed time : %f usec\n",
host_times[0], peak_clk, host_times[0] * 1000.0F/(float)peak_clk);
...
}host_times 배열은 device의 dev_times의 값을 DeviceToHost를 이용하여 복사한 값이다.
실행 결과는 다음과 같다.
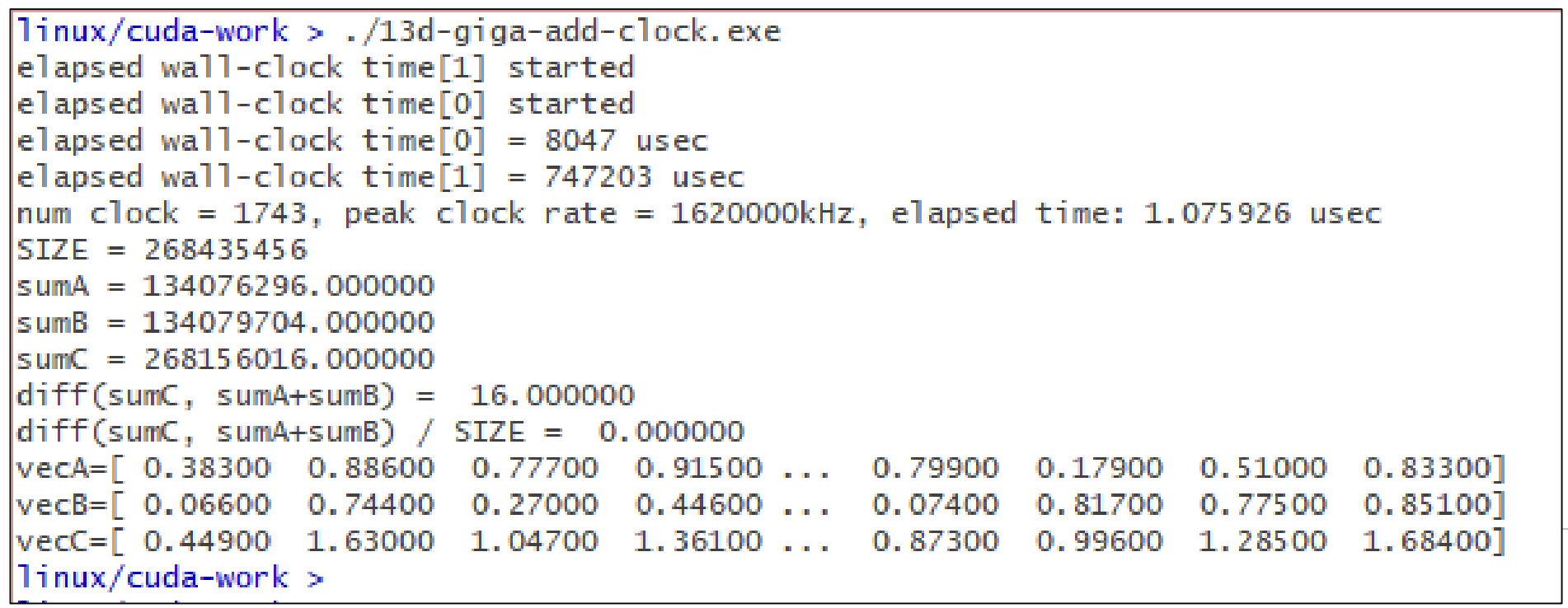
clock rate가 1620000kHz인 것을 확인할 수 있고(CPU는 보통 3GHz, GPU가 좀 낮다), thread 1개가 kernel을 실행하는 시간은 1.07µsec정도 걸렸다.
'대규모병렬컴퓨팅(MPC)' 카테고리의 다른 글
| [MPC/CUDA] Vector Addition (0) | 2022.10.21 |
|---|---|
| [MPC/CUDA] CUDA kernel Launch (1) | 2022.10.21 |
| [MPC/CUDA] Elapsed Time(시간 측정) (1) | 2022.10.13 |
| [MPC/CUDA] Error Check (0) | 2022.10.13 |
| [MPC/CUDA] CUDA Kernel (0) | 2022.10.13 |