

CUDA 커널 실행에 대해 알아보자.
📂 Process and Thread
🏷 Process(프로세스)
Program을 작성한 뒤, 그것을 실행시킨 instance를 말한다. 독립적인 데이터 공간을 확보하고 있다. 즉, Data 영역은 프로세스마다 할당된다.
🏷 Thread(스레드)
Program은 한 개이지만, 내부적으로 여러 개의 독립된 Control flow를 가진 것을 말한다. 스레드끼리는 데이터 공유가 가능하다.
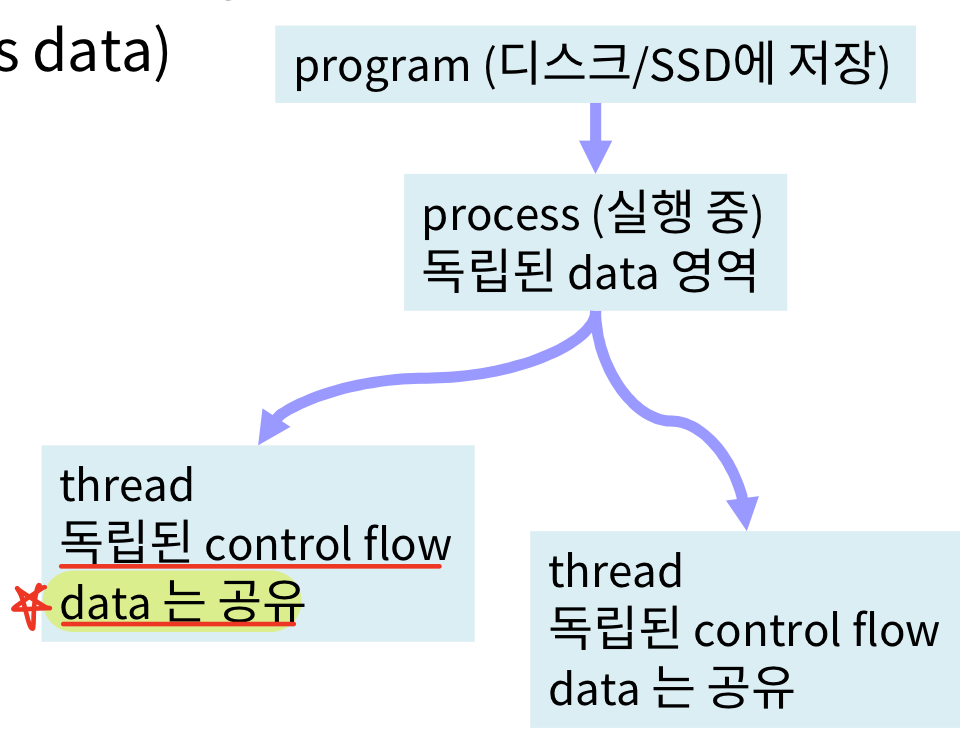
프로세스와 스레드는 OS에 의해 지원된다.
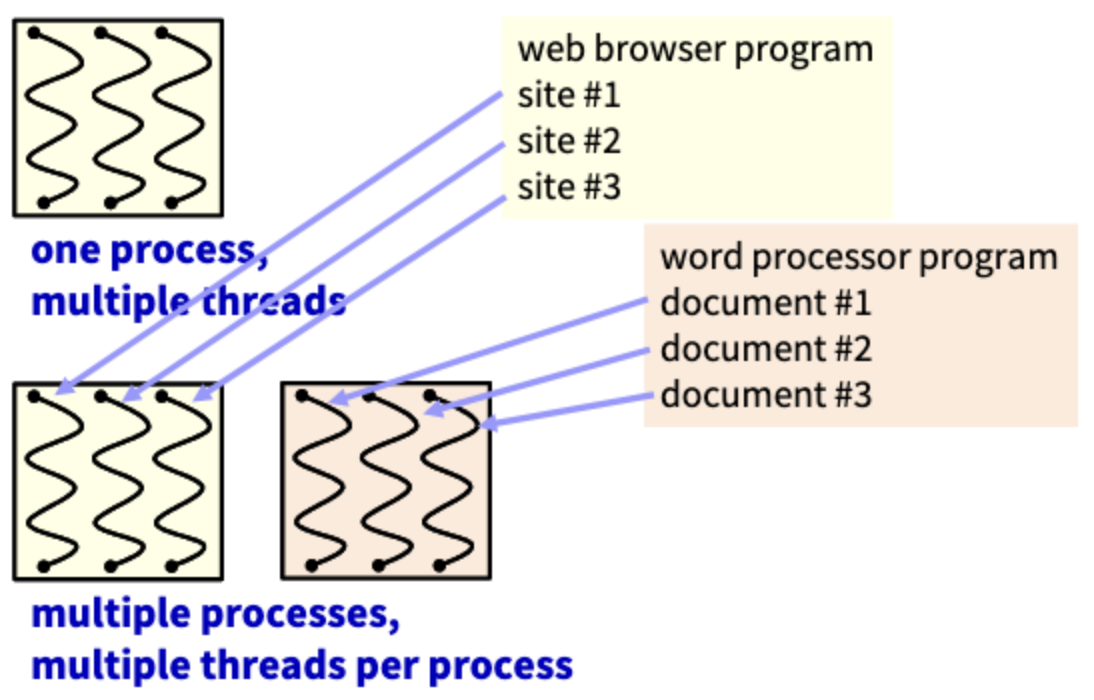
위 그림은 1개의 프로세스에 여러 스레드가 있는 상황과 여러 프로세스에 여러 스레드가 존재하는 상황을 보여준다. 예를 들어, 웹 사이트 안에서 여러 개의 탭을 이용해 여러 site가 동작되는 것은 프로세스가 여러 개 동작하는 것이고, 이 웹 브라우저가 실행 중인 와중에 워드 프로세서와 같은 다른 프로그램을 실행하면, 다른 별도의 프로세스가 실행되는 것이다. 여기서도 마찬가지로 여러 문서를 동시에 작업하면 여러 스레드가 실행된다.
📂 Multiple Core Processors
📄 Time sharing
time sharing의 가장 큰 목적은 (가장 비싼 자원인) 프로세서가 쉬지 않도록 하는 것이다. 그렇게 해서 최고의 효율을 달성하는 게 목표이다.
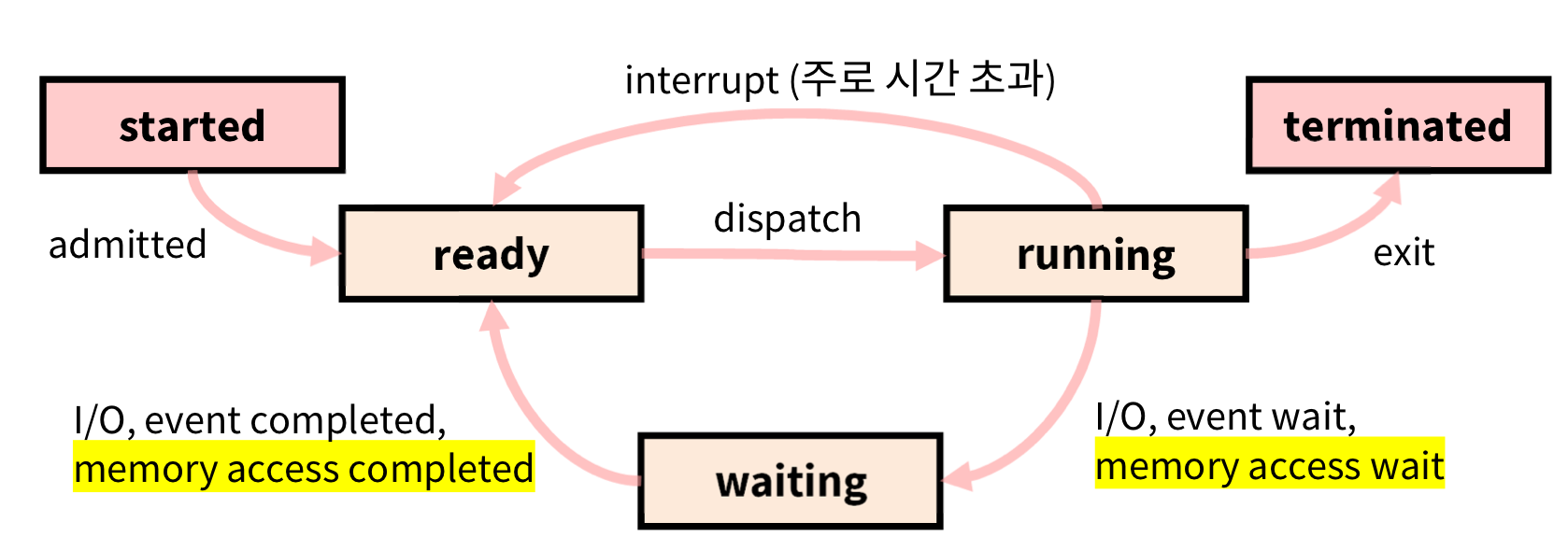
위의 방식으로 동작하는데, 자세한건 운영체제에서 알아보자.
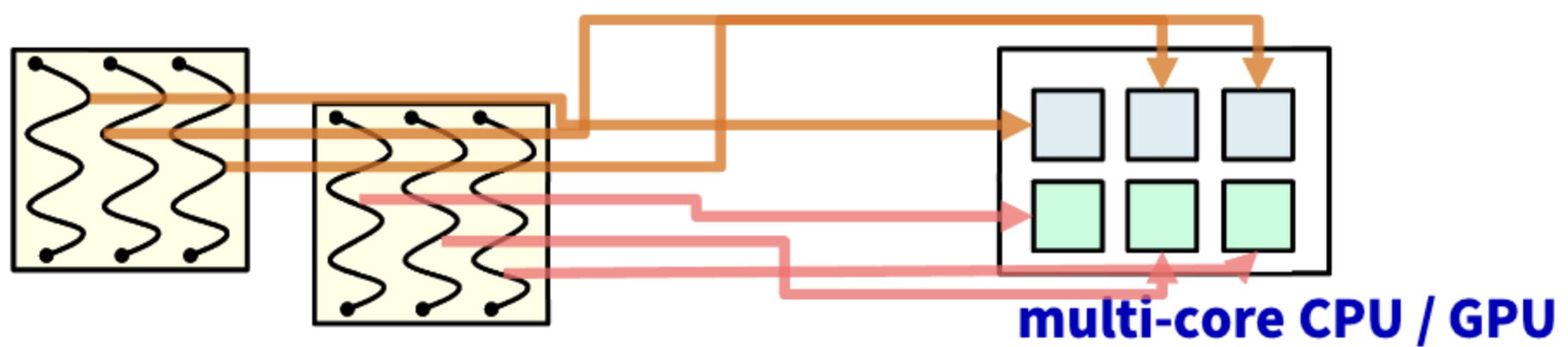
아래의 그림은 multiple process에서 single thread를 통해 병렬 처리를 하는 모습이다.

각각의 Thread를 CPU/GPU의 core 하나하나에 "실제로" 할당해줌으로서 Time sharing을 사용하지 않아도 물리적으로 병렬 처리가 가능하다.
multiple process에서 multiple thread라면 다음과 같은 그림이 될 것이다.
📂 CUDA Programming Model
CUDA의 주 목적은 many-core에 many thread를 실행시키는 것이다. 예를 들어, 1,000,000 threads on 1,000 cores.
Launch는 계층 구조의 관리 모델로 되어있다. 다음과 같은 구조이다.
Grids - Blocks - Threads
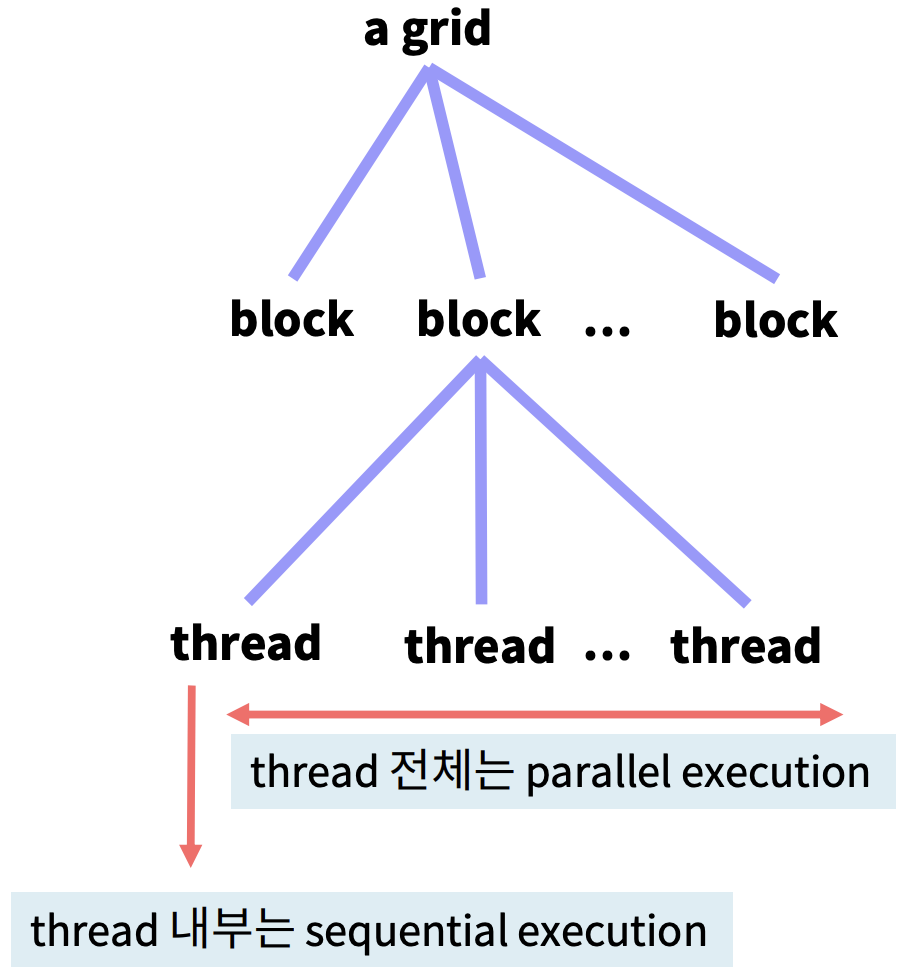
Thread는 Block으로 묶여있고, Block들은 Grid로 묶여있는 구조이다.
CUDA kernel을 실행시키면 커널에서 Grid를 만들어 이 Grid가 실행되는 구조이다. → CUDA kernel program = 1개의 Grid에 대응
그림에 나와있듯, thread 전체는 병렬 수행되지만, 각각의 thread 내부에서 flow는 순차 실행된다.
📄 Calling a Kernel Function
kernel function은 정해진 규약 대로 선언되고, 불러야 한다.
🏷 kernel function 선언
독립적인 함수 형태로,
__global__ void kernel_func(...){
...
}__global__이고, void이어야 한다!!
🏷 kernel function의 호출
__host__ function에서,
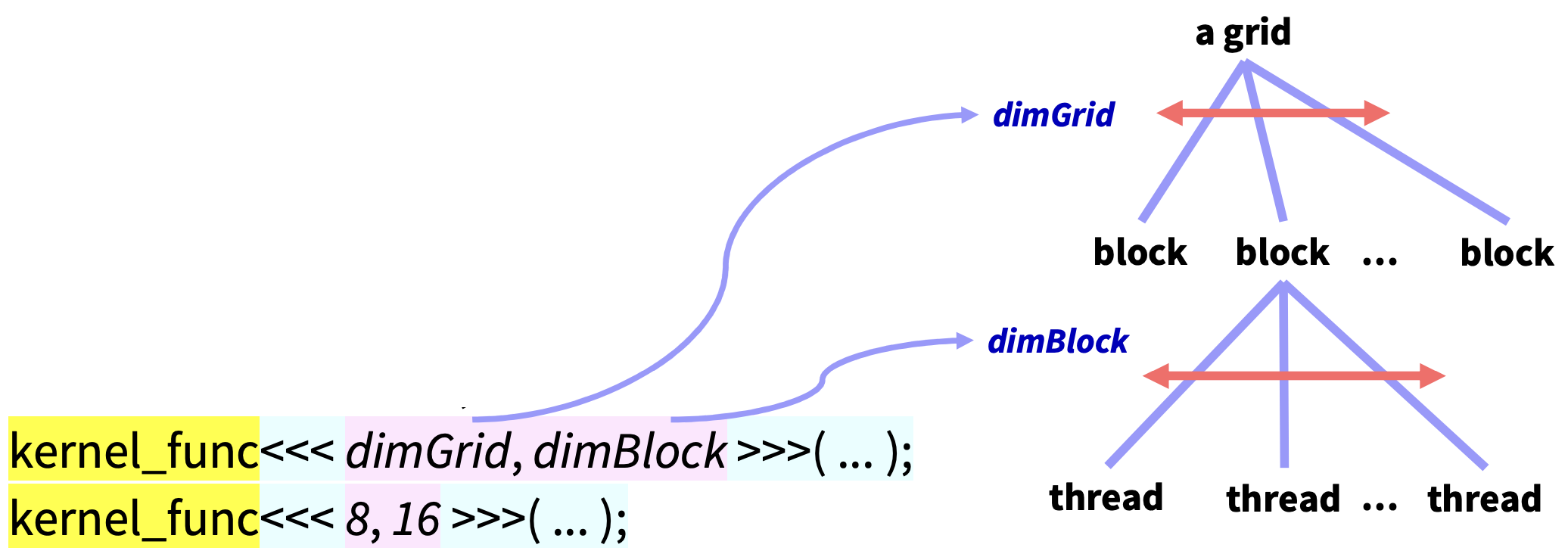
kernel_func<<<dimGrid, dimBlock>>>(...);
kernel_func<<<8, 16>>>(...);<<<,>>> 안에는 각각 2개의 dimension(차원)을 나타내는 변수나 상수가 들어간다.
- dimGrid = Grid 안에 있는 block의 개수
- dimBlock = 하나의 Block 안에 있는 thread의 개수
앞으로는 코드에서 상수 대신 이렇게 변수에 값을 넣고 변수로 설정할 것이다.
📂 IDs and Dimension
Grid, Block 구조는 최대 3차원이다.
- 1D = 1차원 배열
- 2D = 2차원 배열, 행렬, 영상
- 3D = 3차원 그래픽 자료
- ID = 식별 번호
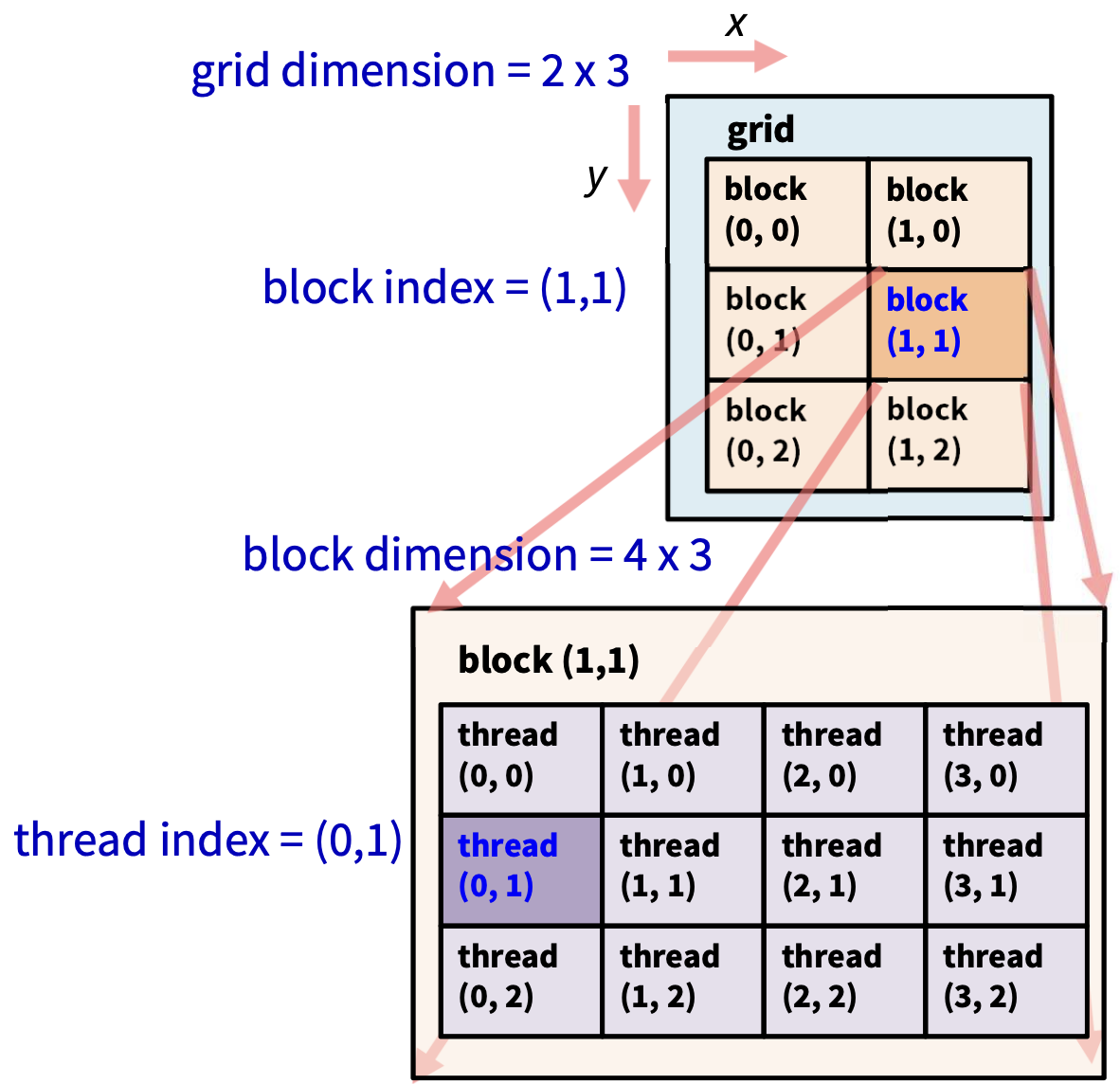
🏷 grid
kernel 마다 1개가 있고, grid dimension은 내부 block의 배치를 말한다.
🏷 block
(x, y, z)는 block의 index(ID)이다. 즉, block의 내부적인 인덱스이다. block dimension은 내부 thread의 배치를 말한다.
🏷 thread
(x, y, z)는 thread의 index(ID)이다.
x, y, z로 나타냈기 때문에 최대 3차원까지 가능하다는 것을 보여준다.
CUDA에서 Vector에 대해 미리 정의해둔 데이터 타입들이 있는데 다음과 같다.

최대 4차원(뒤에 붙는 숫자)까지 존재하고 uint3 = dim3 이다.
각 x, y, z 컴포넌트들은 variable.x, variable.y, variable.z, variable.w로 가져올 수 있다.

uint3와 dim3, char1에 대한 구조체만 살펴보면 위와 같이 되어있어 x, y, z를 가져올 수 있는 것이다.
dim3의 생성자에 의해서 x, y, z의 default 값은 모두 1이다. dim3는 3개까지 argument를 받을 수 있다.
- dim3 dimBlock1D(5 ); → (5, 1, 1)을 의미
- dim3 dimBlock2D(5, 6 ); → (5, 6, 1)을 의미
- dim3 dimBlock3D(5, 6, 7); → (5, 6, 7)을 의미
우리가 이전에 계속 사용해왔던 kernelFunc<<<3, 4>>>(...) 형식 즉, int 1개는 다음과 같이 dim3로 자동 변환이 가능하다.
- kernelFunc<<<3, 4>>>(...);
- kernelFunc<<<dim3(3), dim3(4)>>>(...)
- kernelFunc<<<dim3(3, 1, 1), dim3(4, 1, 1)>>>(...)
CUDA 컴파일러가 숫자를 1차원 변수로 보고 이것을 3차원 변수로 확장해서 알려주는 것이다.
이제 이것을 실제로 적용해보자!!
📄 kernel Launch Syntax
kernel function의 호출을 보면, __host__ function에서
dim3 dimGrid(100, 50, 1); // 100*50*1=5000 thread blocks
dim3 dimBlock(4, 8, 8); // 4*8*8=256 threads per block
kernel_func<<<dimGrid, dimBlock>>>(...);이와 같이 dimGrid, dimBlock 변수로 미리 선언을 하고 이것을 Call할 때 넣어주자! 코드를 살펴보면,
Grid 안에 100*50*1의 3차원 형태의 block들이 만들어지고, 그 block 안에는 4*8*8의 3차원 형태의 thread들이 만들어지게 되는 것이다. 따라서, 총 Thread 수는 5000*256 개가 된다.
📄 CUDA pre-defined variables
thread를 실행시키면 thread 내부에서 pre-define된 변수들이 미리 설정되어 들어온다. 이 변수들은 모든 thread에서 사용이 가능하다. 이 변수들을 이용해 내가 속한 thread가 어느 block에 속해있는지, 몇 개의 block, thread가 있는지...등을 알 수 있다.
변수들은 다음과 같다.
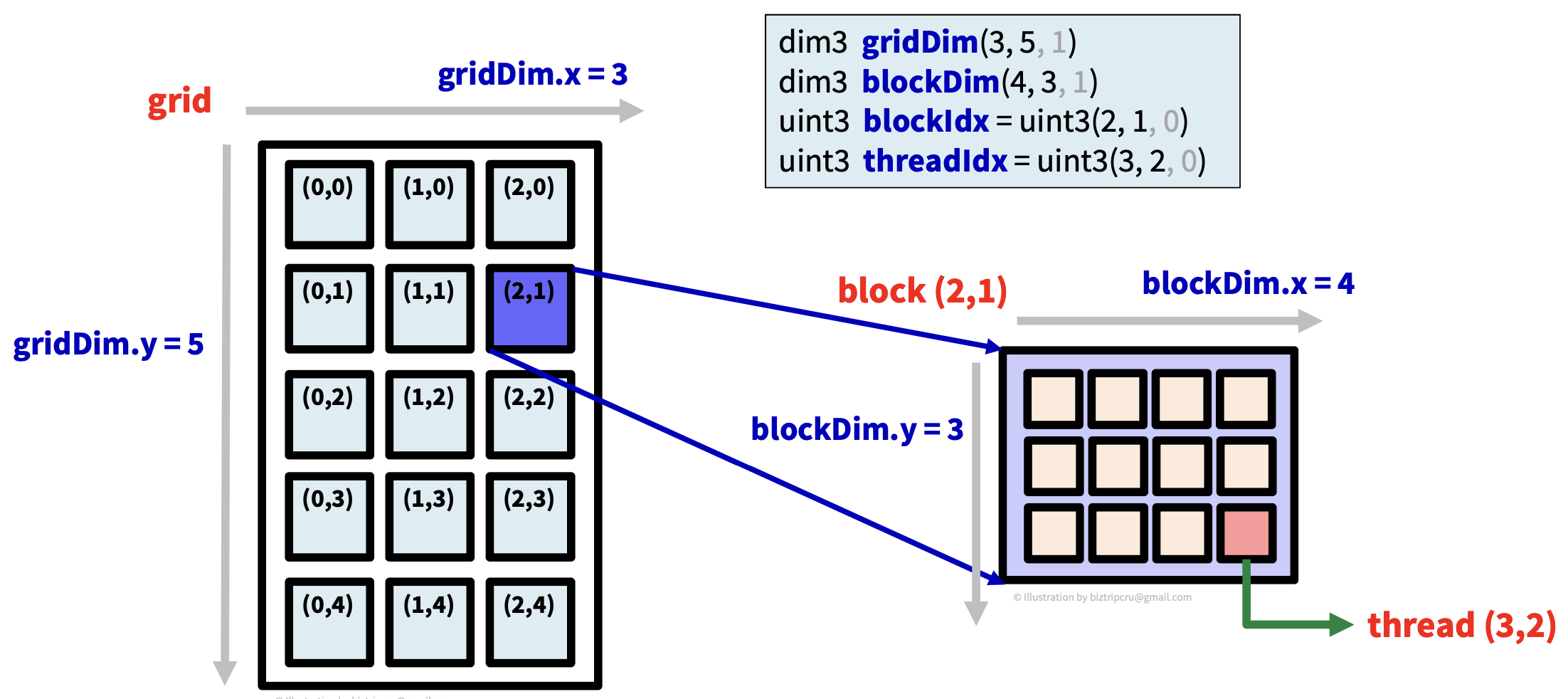
- dim3 gridDim → gird의 차원 / gridDim.x
- dim3 blockDim → block의 차원 / blockDim.x
- uint3 blockIdx → grid 안의 block의 인덱스 / blockIdx.x
- uint3 threadIdx → block 안의 thread의 인덱스 / threadIdx.x
- int warpSize → warp 안에 있는 thread의 개수
이제 1차원을 예시로 한 번 살펴보자.
📄 Example : 1D Layout
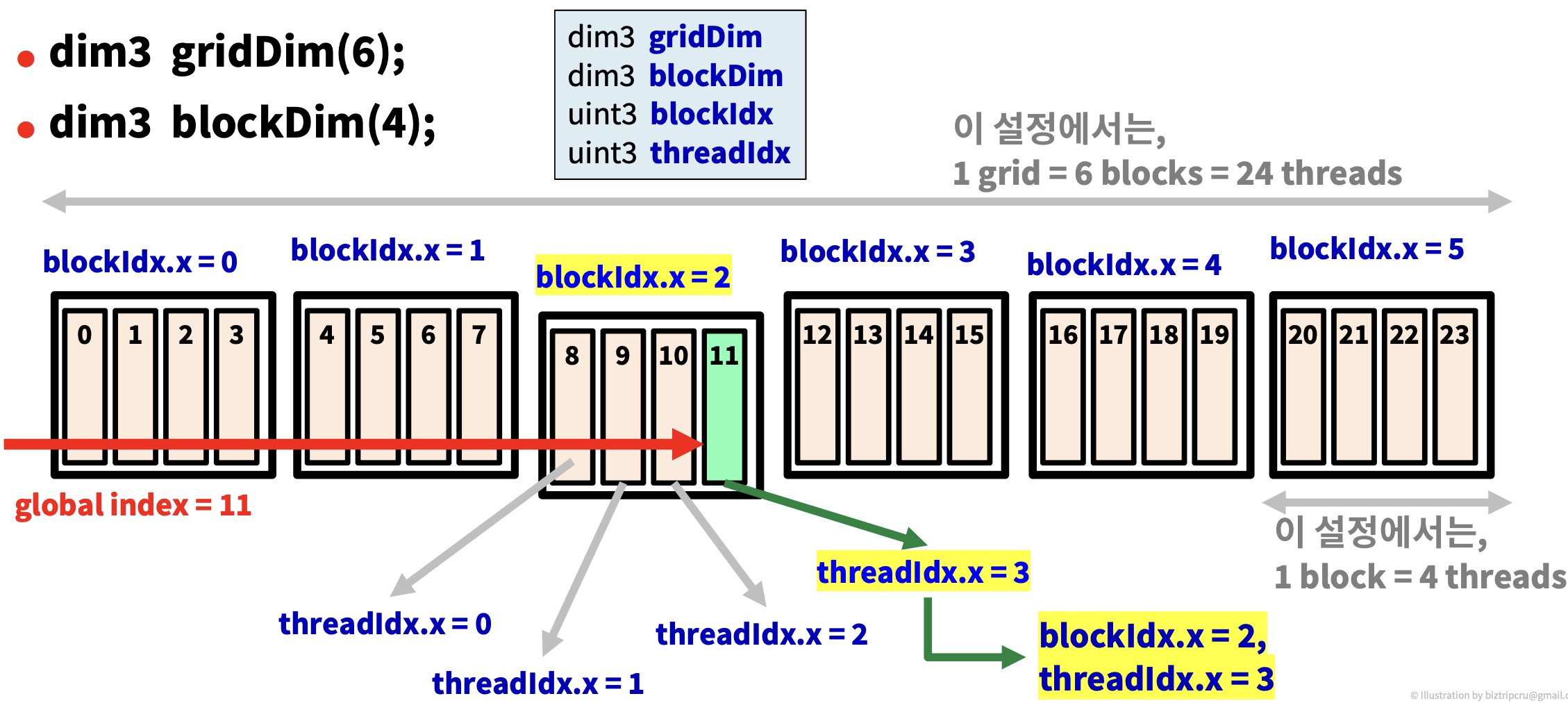
gridDim(6), blockDim(4)에서 6개의 block과 각 block 당 4개의 thread가 생성된 것을 알 수 있다.
만약 Thread의 global index를 알고 싶다면, 현재 thread가 속해있는 block의 인덱스까지 이동한 뒤에 해당 block 안에서 thread의 인데스를 찾으면 된다. 이를 식으로 표현하면 다음과 같다.
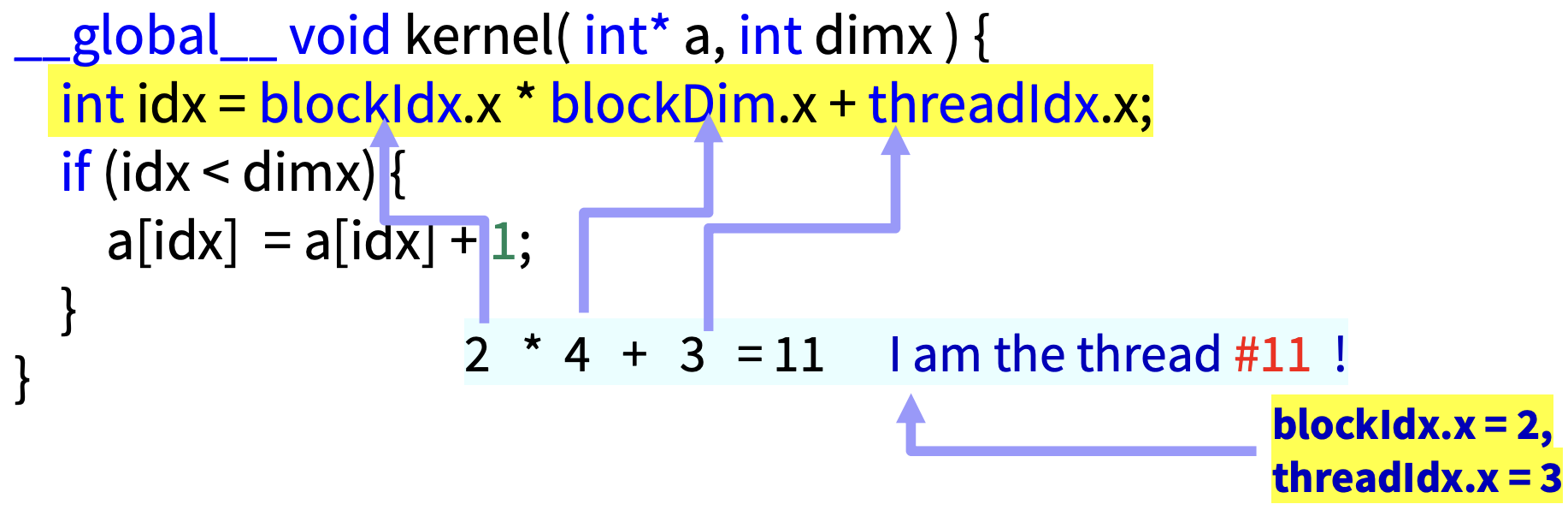
int idx = blockIdx.x * blockDim.x + threadIdx.x
blockDim은 block 안의 thread 개수이므로 위와 같은 식이 성립된다.
📄 2D Layout
2차원, 3차원이라고 다를 것 없이 x에 대해 수행하던 것을 y에 대해서도 똑같이 수행해주면 된다.
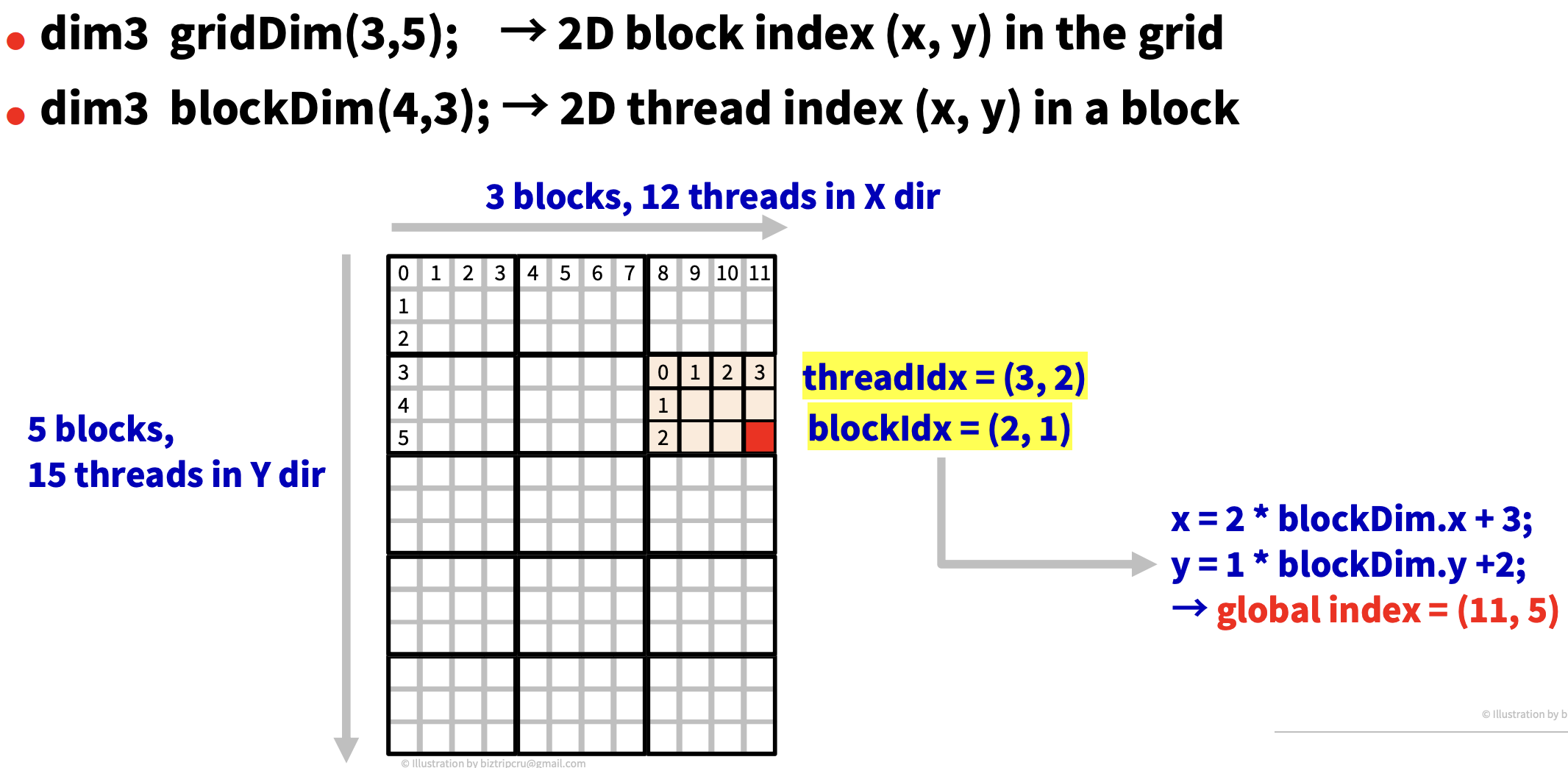
이를 커널 함수 안에서 인덱스를 구하는 코드로 나타내면 다음과 같다.

(gx, gy)는 global index이다. 즉, 2차원 행렬 상의 위치이다.
📂 CUDA Architecture for Threads
CUDA 아키텍쳐 관점에서 thread를 처리하는 것을 살펴보자.
🏷 SP (Streaming Processor)
single thread를 위한 프로세서이다. ALU 정도의 낮은 성능을 가지고 있다. Core라고도 알려져있다.
이를 이용해 성능은 낮지만 그 개수를 늘리는 방법을 채택했다.
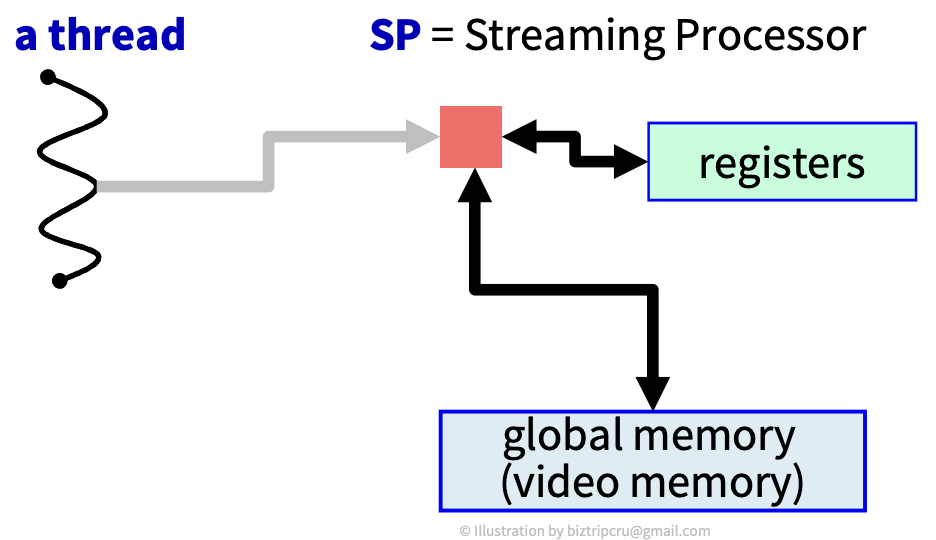
SP는 내부적으로는 매우 많은 레지스터(register)를 가지고 있어, thread 전환에 비용이 거의 없는 zero context switching.
또한, SP에서 직접 Global memory에 접근(access)이 가능하다.
🏷 SM (Streaming multi-processor)
thread block을 위한 것으로 1개의 thread가 아닌, block을 돌린다. 실제로는 이 SM을 가지고 돌리게 된다. 일종의 하나의 CPU처럼 동작한다.
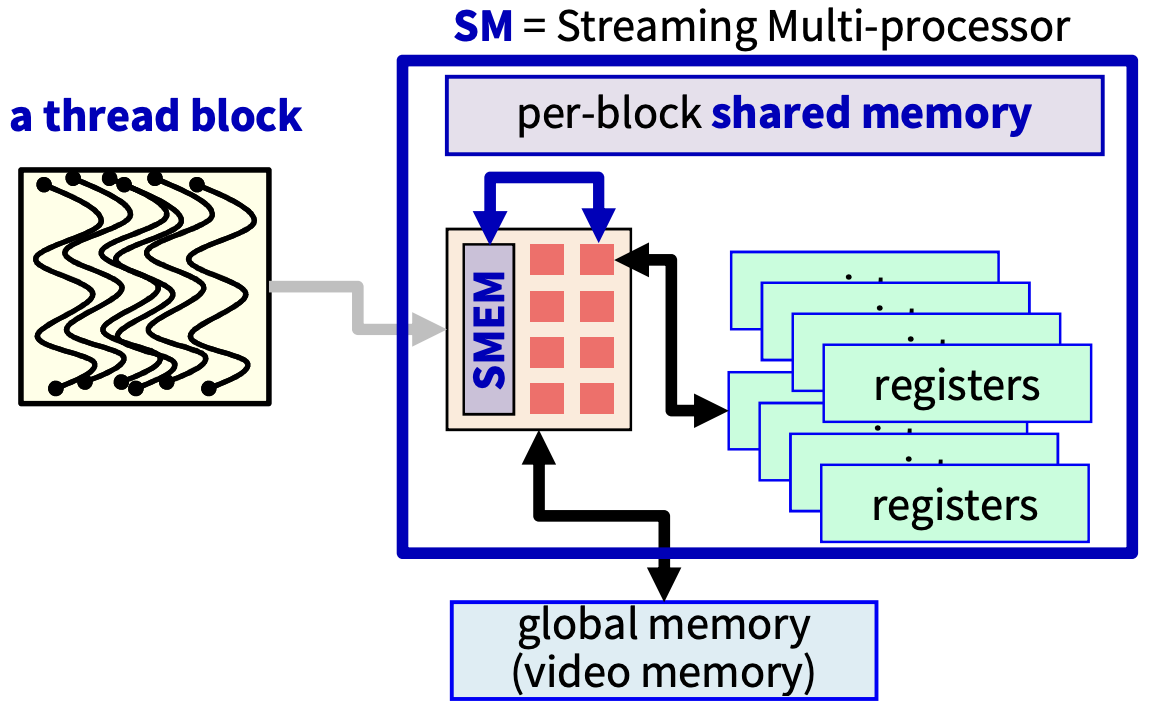
per-block shared memory는 Core들이 같이 사용하는 메모리이다.
위의 예를 보면, a thread block을 보면 1024개의 thread로 이루어져있고, SM은 SP들의 집합으로 32개의 SP(32개의 Core)로 이루어져 있다.
SM의 물리적 한계는 Thread Block의 최대 크기이다.
SM에는 32개의 SP가 들어있기 때문에, 동시에 32개의 thread만 실행 가능하다. 1024개의 thread 중 대부분은 대기 상태이다.
CUDA device는 매우 많은 SM들로 이루어져있다. 보통 thread block 개수 > SM 개수 이다.
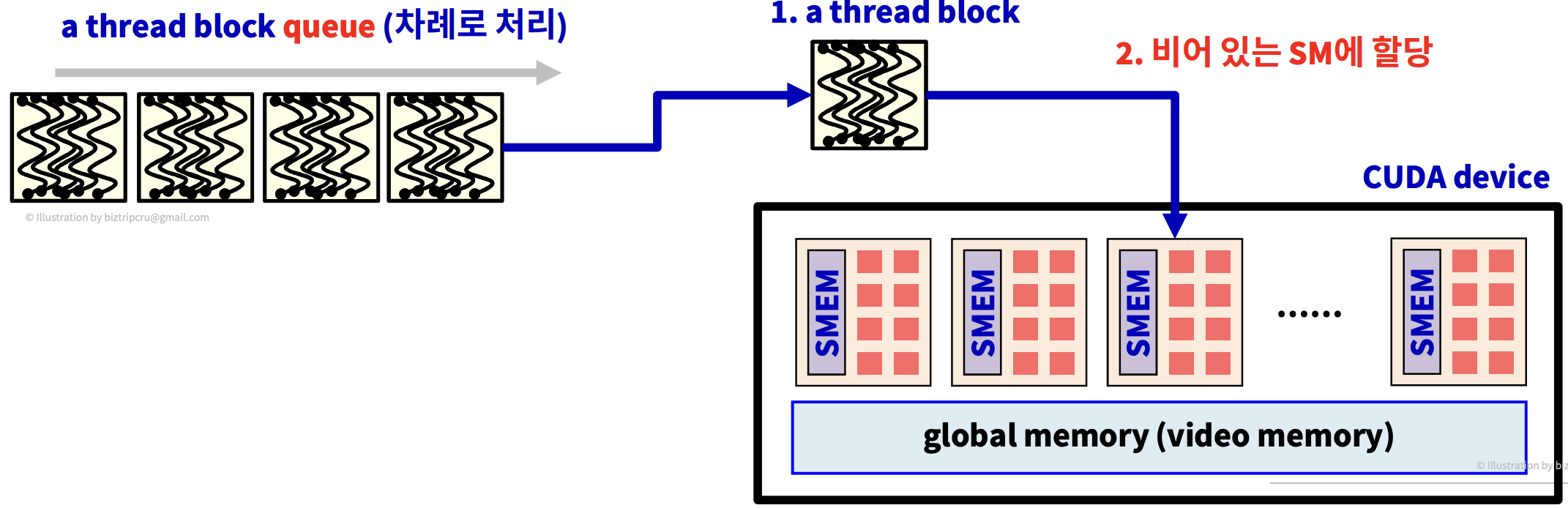
먼저, Thread의 개수가 매우 많으면 1024개씩 나누어 여러 개의 block으로 만들고 이 block들을 Queue에 넣어둔다. 그리고 SM이 한 Thread block을 실행 완료시키면 Queue에 있는 다음 thread block이 이 비어 있는 SM에 할당되는 방식으로 동작한다.
전체적으로 보면, SM이 thread block을 하나씩 가져가서, 실행하고, 제거하고 다시 다른 thread block을 가져오고... 이 동작들을 반복하게 된다.
'대규모병렬컴퓨팅(MPC)' 카테고리의 다른 글
| [MPC/CUDA] Giga-size Vector Addition (4) | 2022.10.22 |
|---|---|
| [MPC/CUDA] Vector Addition (0) | 2022.10.21 |
| [MPC/CUDA] Elapsed Time(시간 측정) (1) | 2022.10.13 |
| [MPC/CUDA] Error Check (0) | 2022.10.13 |
| [MPC/CUDA] CUDA Kernel (0) | 2022.10.13 |