

앞선 포스팅에서 했던 1차원 배열의 합을 구하는 것을 배열의 크기를 매우 키우고, CPU와 CUDA를 사용했을 때의 실행 시간을 비교해보자.
📂 vecadd-host.cpp
SIZE가 1024*1024인 배열에 값을 넣기 위해 rand() 함수를 이용하자.
#include "./common.cpp"
// set random value of [0.000, 1.000) to dst array
void setRandomData(float* dst, int size){
while(size--){
*dst++ = (rand()%1000)/1000.0F;
}
}
// get total sum of dst array
float getSum(float* dst, int size){
register float sum = 0.0F;
while(size--){
sum += *dst++;
}
return sum;
}다음은 main함수이다.
const unsigned SIZE = 1024*1024; // 1M elements
int main(void){
//host-side data
float* vecA = new float[SIZE];
float* vecB = new float[SIZE];
float* vecC - new float[SIZE];
//set random data to A&B
srand(0);
setRandomData(vecA, SIZE);
setRandomData(vecB, SIZE);
chrono::system_clock::time_point time_begin = chrono::system_clock::now();
for(register unsigned i=0;i<SIZE;++i){
vecC[i] = vecA[i] + vecB[i];
}
chrono::system_clock::time_point time_end = chrono::system_clock::now();
chrono::microseconds time_elapsed_msec
= chrono::duration_cast<chrono::microseconds>(time_end - time_begin);
printf("elapsed wall-clock time = %ld usec\n", (long)time_elasped_msec.count());
//check the result
float sumA = getSum(vecA, SIZE):
float sumB = getSum(vecB, SIZE):
float sumC = getSum(vecC, SIZE):
float diff = fabsf(sumC - (sumA+sumB);
printf("..."); // 위의 sum값들 모두 출력
printf("diff(sumC, sumA+sumB) = %f\n", diff);
printf("diff(sumC, sumA+sumB)/SIZE = %f\n", diff/SIZE);
...
delete[] vecA;
delete[] vecB;
delete[] vecC;
return 0;
}여기서 diff를 계산하는 이유는 이론상으로는 이 값이 0.0이 나와야하지만, floating point 때문에 오차가 발생한다. 이를 SIZE로 나누어 개당 오차를 확인해 이 값이 0.0에 가까우면 오차가 거의 없다는 것을 확인하기 위해서이다.
결과는 다음과 같다.
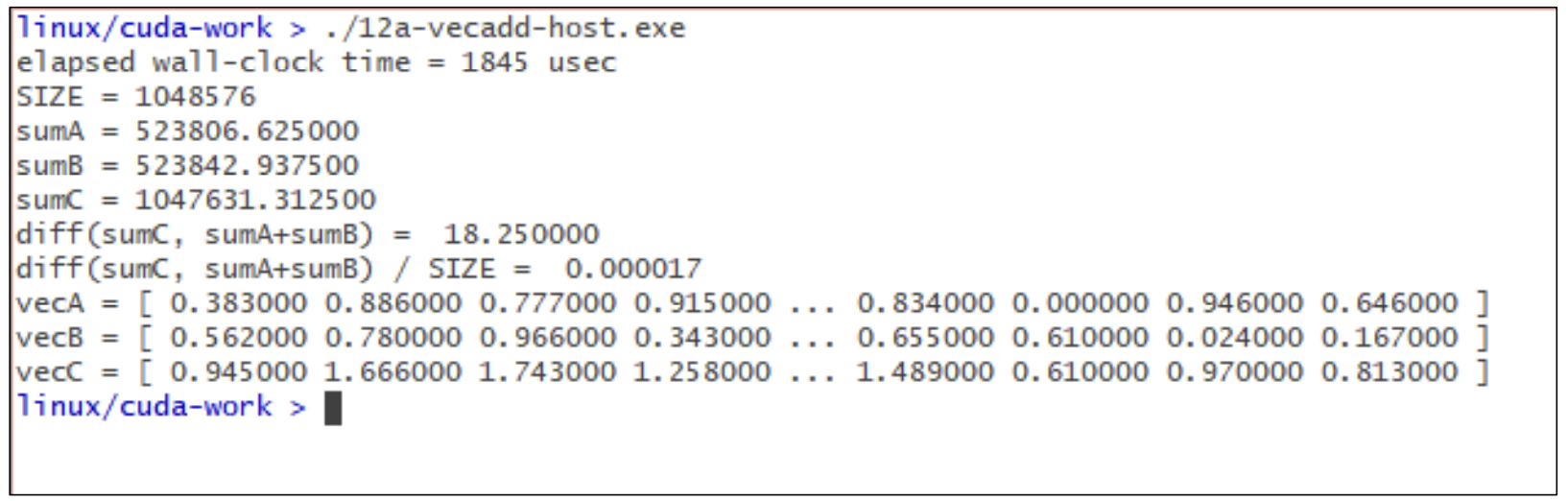
Host에서 수행했을 때, 총 wall-clock time은 1845µsec가 걸렸고, diff/SIZE도 0.0에 매우 근접하니 계산에 맞다고 볼 수 있다.
이건 CPU에서 for-loop를 이용하여 나온 결과이다.
📂 vecadd-host-kernel.cpp
위에 for-loop 안에서 식을 돌린 것은 kernel 함수로 뺴서 다시 계산을 수행해보자. 편의를 위해 랜덤값 넣기, 배열의 합 구하기, 배열 출력하기는 "common.cpp"에 만들어 넣어두고 사용하였다.
#include "./common.cpp"
const unsigned SIZE = 1024*1024;
void kernelVecAdd(unsigned i, float* c, const float* a, const float* b){
c[i] = a[i]+b[i];
}
int main(void){
...
//위의 코드와 동일
...
ELAPSED_TIME_BEGIN(0);
for(register unsigned i=0;i<SIZE;++i){
kernelVecAdd(i, vecC, vecA, vecB);
}
ELAPSED_TIME_END(0);
...
// print result
...
}이에 대한 결과는 다음과 같다.
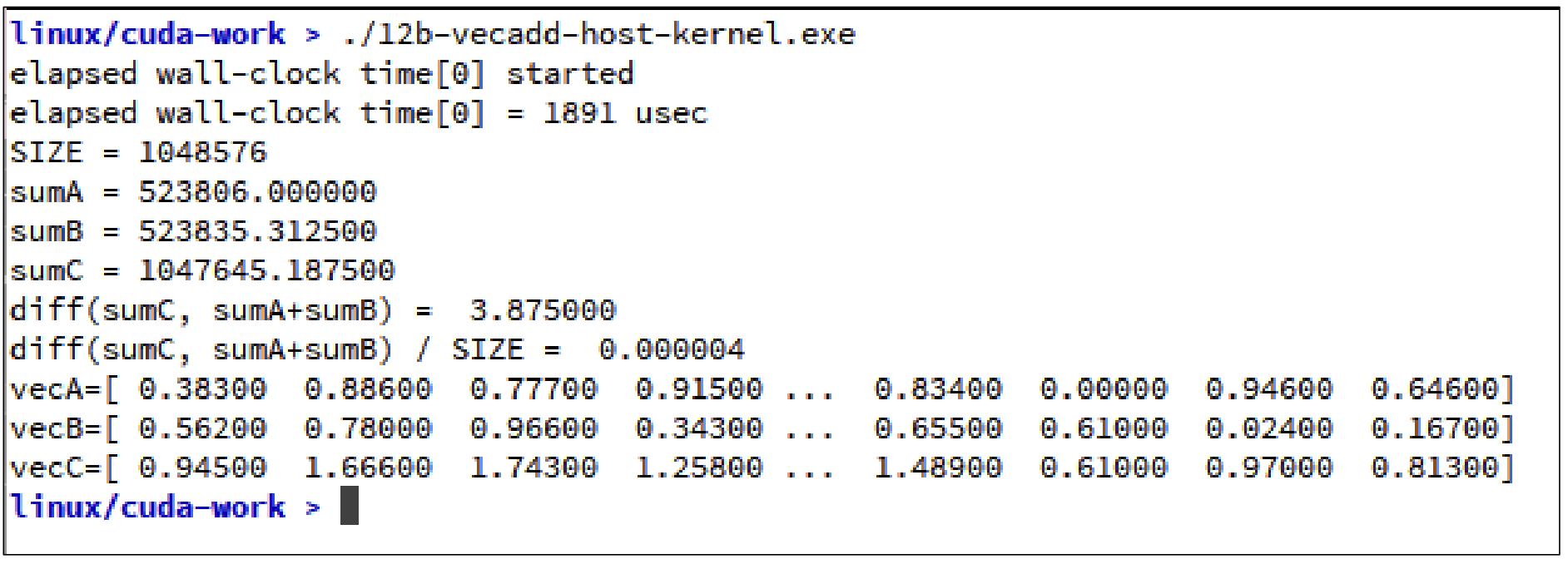
앞선 코드와 크게 차이가 없는 것을 확인할 수 있다.
📂 vecadd-single.cu
이제 진짜로 CUDA를 이용하여 코드를 작성해볼껀데, 우선 CUDA의 코어를 한 개만 쓰도록 설정해보자.
__global__ void singleKernelVecAdd(float* c, const float* a, const float* b){
for(register unsigned i=0;i<SIZE;++i)
c[i] = a[i] + b[i];
}
}
int main(void){
...
ELAPSED_TIME_BEGIN(1); // RAM <--> VRAM으로 copy하는 시간 포함
cudaMemcpy(dev_vecA, vecA, SIZE*sizeof(float), cudaMemcpyHostToDevice);
...
//CUDA Kernel call
ELAPSED_TIME_BEGIN(0); // 순수하게 커널만 실행되는 시간
singleKernelVecAdd<<<1, 1>>>(dev_vecC, dev_vecA, dev_vecB);
cudaDeviceSynchronize(); // 0번 타이머 종료
ELAPSED_TIME_END(0);
...
cudaMemcpy(vecC, dev_vecC, SIZE*sizeof(float), cudaMemcpyDeviceToHost);
ELAPSED_TIME_END(1); // 1번 타이머 종료
...
}<<<1, 1>>>에서 알 수 있듯, Core를 한 개만 사용하였다. 그 결과는 아래와 같다.
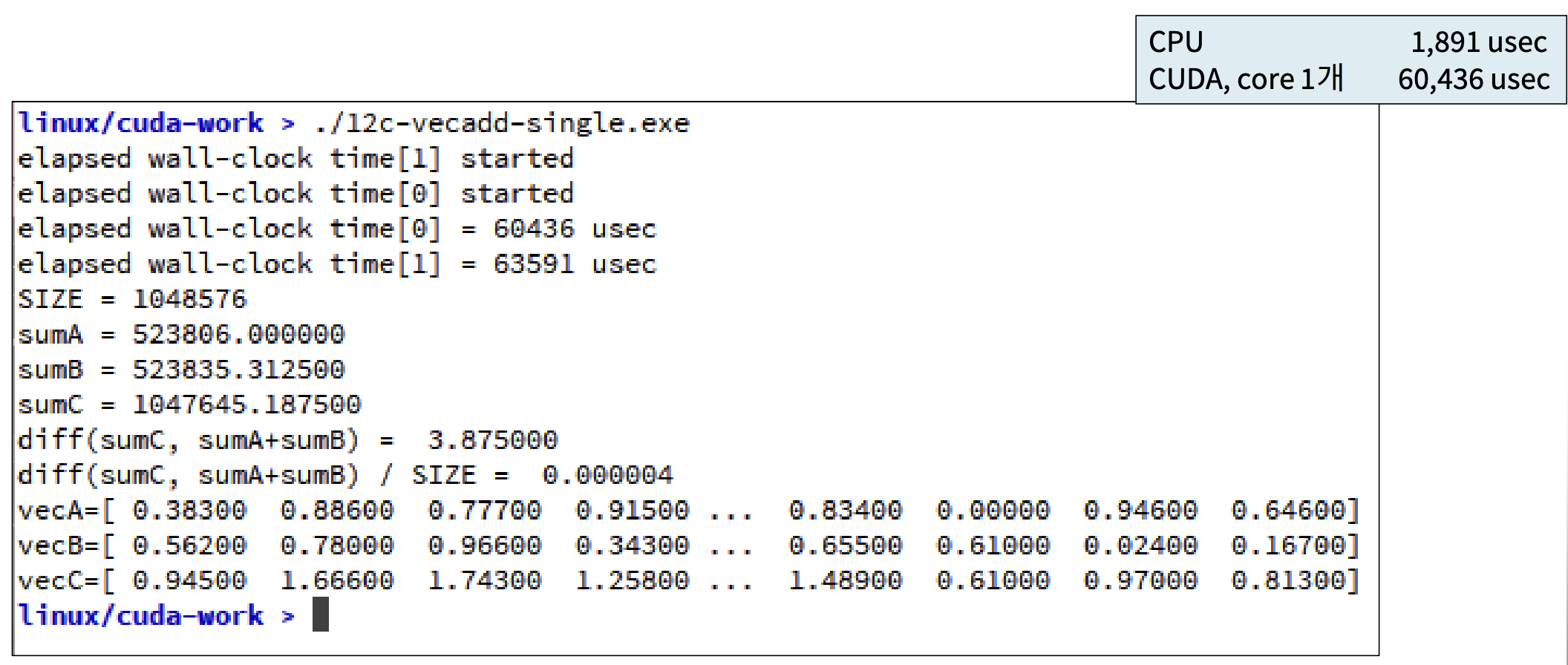
총 60,436µsec가 걸린 것을 확인할 수 있다. 왜 더 느리지? 클럭 속도는 GPU보다 CPU가 더 빠르기 때문이다.
📂 vecadd-error.cu
이 코드는 실행시키면 에러가 나는 코드이다. 이 에러의 원인에 대해 알아보자.
이제 위의 kernelVecAdd 함수를 바꿔 각 thread에서 수행되도록 해보자. 그리고 SIZE개만큼의 thread를 이용해 계산을 수행하자.
__global__ void kernelVecAdd(float* c, const float* a, const float* b, unsigned n){
unsigned i = threadIdx.x;
if(i<n){
c[i]=a[i]+b[i];
}
}
int main(void){
...
ELAPSED_TIME_BEGIN(0);
kernelVecAdd<<<1, SIZE>>>(dev_vecC, dev_vecA, dev_vecB, SIZE);
ELAPSED_TIME_END(0);
...
}이렇게 되면 threadIdx.x에 의해 각 thread는 딱 1번의 덧셈 연산만을 수행할 것이다. 커널 함수 안에 조건문이 있는 이유는, 배열의 크기보다 thread의 개수가 많을 수 있기 때문에 thread index가 주어진 배열의 크기보다 더 큰 인덱스를 참조하지 못하도록 설정한 것이다.
결과는 다음과 같다. 오류가 발생한다.
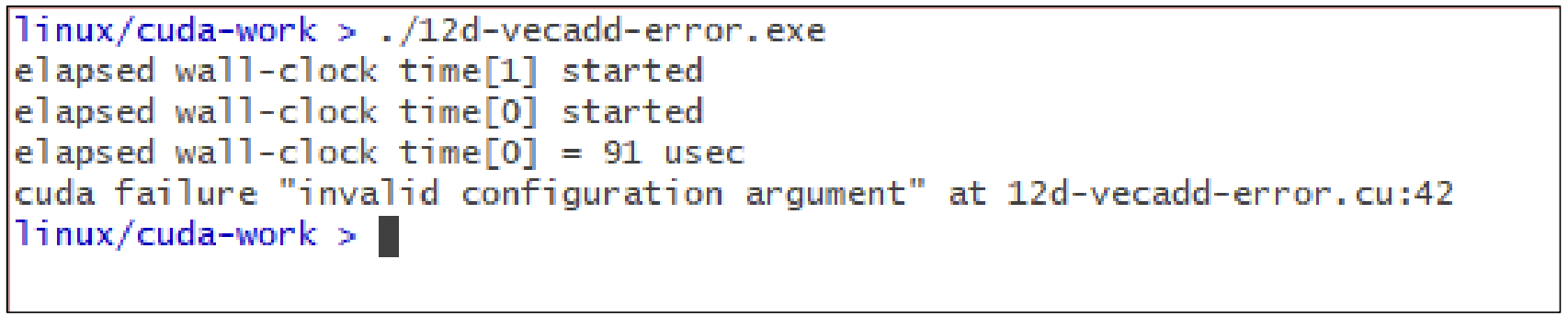
위의 CUDA kernel call 부분을 보면 <<<1, SIZE>>>로 설정되어 있는데, 이 말은 1M(1024*1024)개의 thread를 동시에 사용하도록 요구하는 것이다. SM에서 1M개의 thread를 동시 실행하는 것은 불가능하다. 우리의 컴퓨터에는 1M개의 Core가 없기 때문에!
따라서, 위와 같이 "invalid configuration argument" 즉, CUDA Kernel의 구성이 잘못 되었다는 에러가 발생한 것이다.
실제로는 1024개가 한계이다.
이런 오류가 발생하지않도록 하려면 어떻게 해야할까?
📂 vecadd-dev.cu
그렇다면, SIZE개의 core 사용을 요구할 수 있는 형태로 코드를 바꿔보자.
//CUDA kernel Call
ELAPSED_TIME_BEGIN(0);
kernelVecAdd<<<SIZE/1024, 1024>>>(dev_vecC, dev_vecA, dev_vecB, SIZE);
cudaDeviceSynchronize();
ELAPSED_TIME_END(0);1차원 배열에서 SIZE가 1M개인 것을 다음과 같이 분리하자.
block에 들어갈 수 있는 thread의 개수는 최대 1024개로 정해져있기 때문에, block의 개수를 조정하는 것이다.(위에서는 1이였다.)
- SIZE = 1M
- gridDim → (SIZE/1024) blocks → 1024 blocks
- blockDim → 1024 threads
이를 이용하기 위해서는 block이 여러 개 생겼으므로 thread의 global index를 구해야한다. 그래서 kernelVecAdd 코드는 다음과 같이 바뀌게 된다.
__global void kernelVecAdd(float* c, const float* a, const float* b, unsigned n){
unsigned i = blockIdx.x * blockDim.x + threadIdx.x;
if(i<n){
c[i] = a[i] + b[i];
}
}blockIdx.x * blockDim.x + threadIdx.x를 해야 global index가 나온다는 것을 다시 한 번 확인하자!
이렇게 설정하고 다시 실행시킨 결과는 다음과 같다.
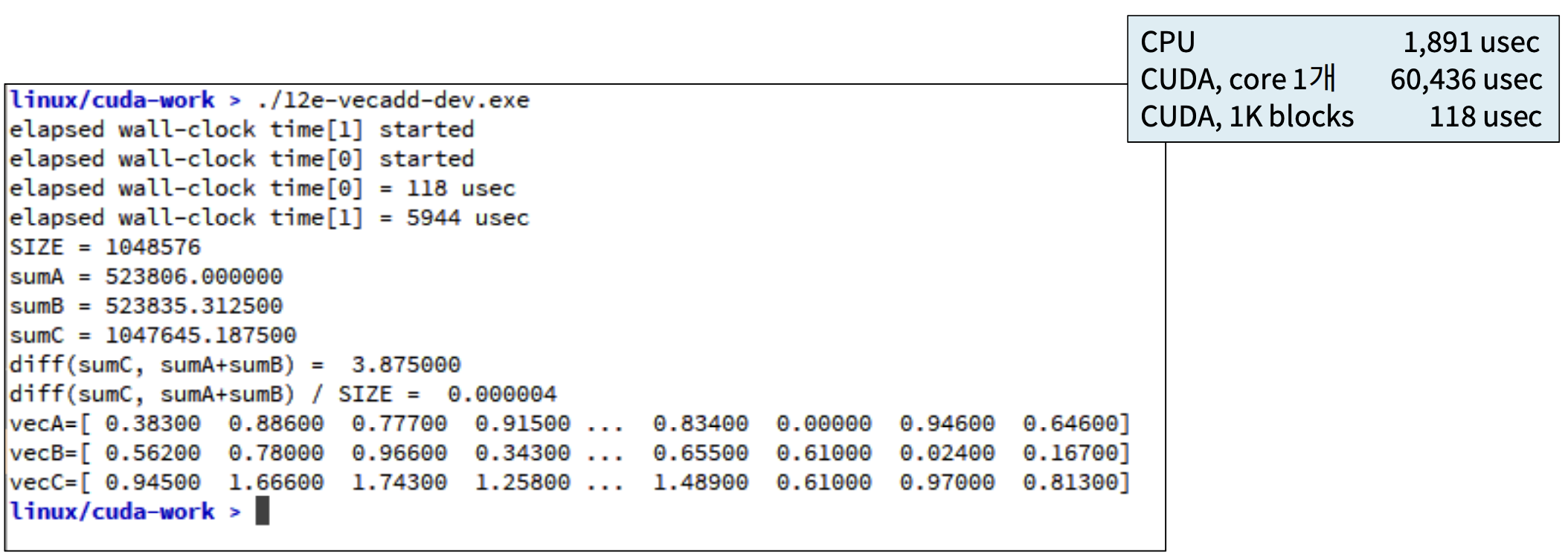
결과로 118µsec가 나왔는데, 이는 vecadd-host.cpp에서 실행한 결과보다 매우 좋은 결과임을 알 수 있다.
'대규모병렬컴퓨팅(MPC)' 카테고리의 다른 글
| [MPC/CUDA] Giga-size Vector Addition (4) | 2022.10.22 |
|---|---|
| [MPC/CUDA] CUDA kernel Launch (1) | 2022.10.21 |
| [MPC/CUDA] Elapsed Time(시간 측정) (1) | 2022.10.13 |
| [MPC/CUDA] Error Check (0) | 2022.10.13 |
| [MPC/CUDA] CUDA Kernel (0) | 2022.10.13 |