

📄 Single CPU
이전에 포스팅했던 Single CPU 기반의 Vector addition을 보면 다음과 같다.
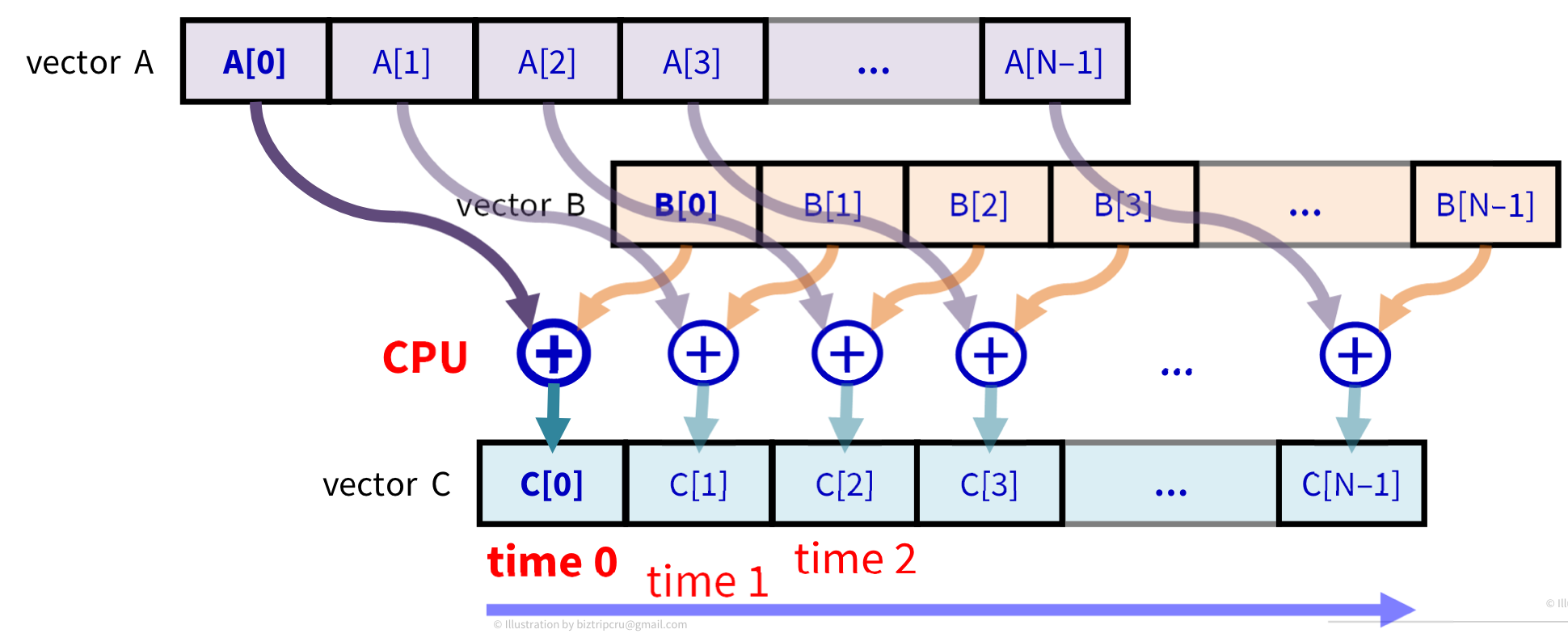
CPU는 1개의 코어를 가지고 있는 상태이고 time 0, time 1, time 2... 와 같이 시간을 달리하여 순차 처리를 한다.
📄 many-core GPU
다음은 many core인 GPU에서의 동작을 보자.
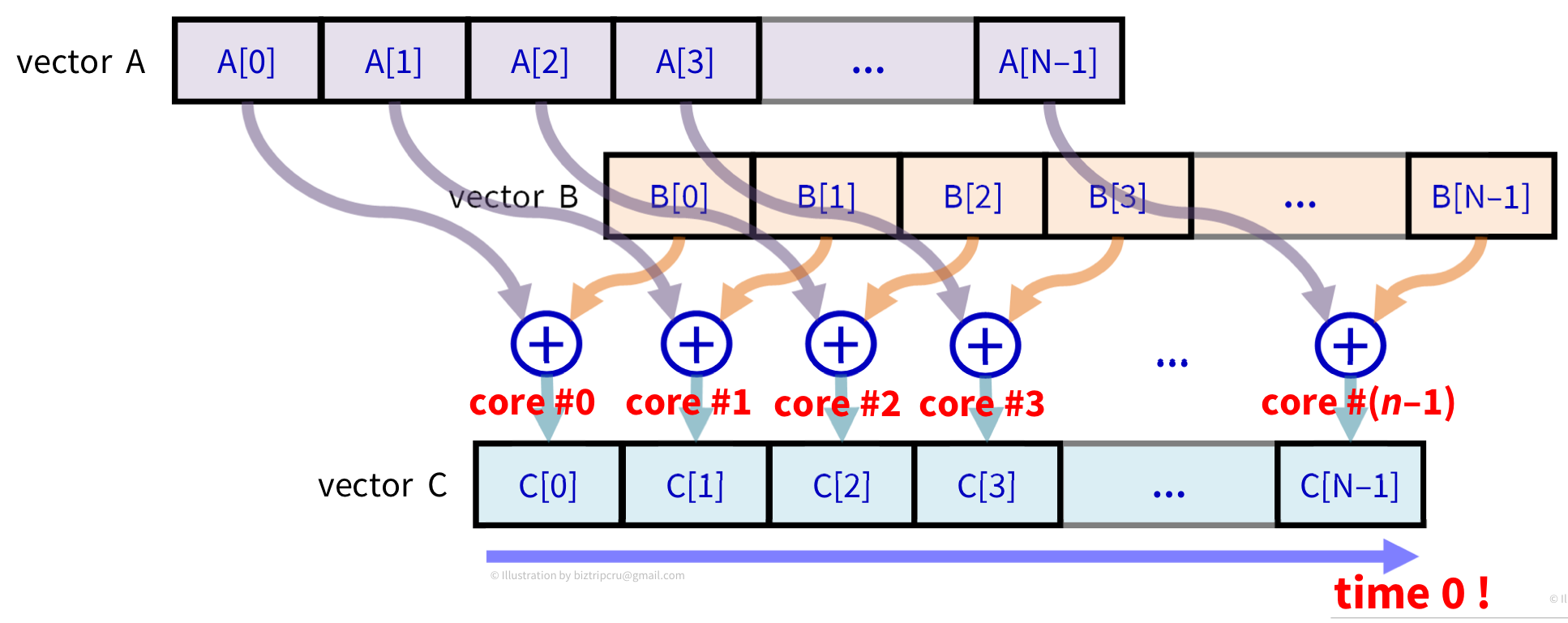
core#0, core#1 ... core#(n-1)과 같이 N개의 코어를 모두 사용하여 time 0에 addition을 끝낼 수 있다.
📂 Scenario : CUDA vector addition
그럼 이 CUDA Vector addition의 시나리오를 보자.
총 5개의 step으로 동작된다.
1️⃣ Host-side
host에서 source data인 A, B 배열과 결과를 저장할 C 배열을 만든다. 즉, source data를 확보하는 것이다.
2️⃣ Data copy host → device
cudaMemcpy를 통해 host에서 device로 배열을 복사한다. 즉, Data를 VRAM으로 copy하는 것이다.
3️⃣ Addition in CUDA
데이터를 복사받은 CUDA device에서 Kernel을 launch 한다. 즉, 커널을 실행해서 CUDA device에서 작업을 수행하는 것이다.
이때 결과는 device memory에 저장된다.
4️⃣ Data copy device → host
cudaMemcpy를 통해 device에서 host로 계산한 결과를 복사한다. 즉, 계산 결과를 RAM의 C 배열로 넘기는 것이다.
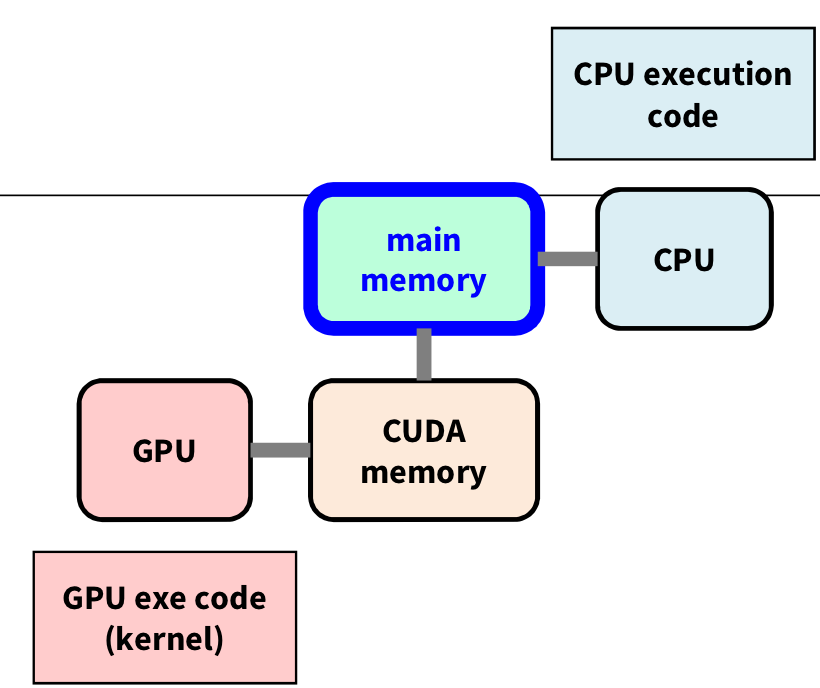
5️⃣ Host-side
결과를 프린트하거나, 다른 필요한 동작을 수행한다.
📂 Function Call vs Kernel Launch
C/C++에서 함수를 호출하는 것을 function call이라 한다.
void func_name(...);
for(int i=0;i<SIZE'++i){
func_name(...); // function call
}반면, CUDA에서 커널을 구현하는 것을 Kernel launch라 한다.
__global__ void kernel_name(int param, ...);
kernel_name<<<1,SIZE>>>(param, ...);__global__이 붙으면 CUDA의 kernel function이다. <<<1,SIZE>>>는 몇 개의 Core를 사용할지 결정하는 것인데 뒤에서 자세하게 배울 것이다.
이 CUDA kernel Launch를 자세히 보자.
📂 CUDA Kernel Launch
CUDA kernel function을 예로 들면 다음과 같은 코드가 있다.
__global__ void add_kernel(int* c, const int* a, const int* b){
int i = threadIdx.x;
c[i]=a[i]+b[i];
}여기서 주목해야할 부분은 threadIdx.x 이 부분이다.
CUDA 커널에서 인덱스 변수를 자동으로 설정해주어, Kernel function이 실행될 때 kernel function마다 자신의 Index를 체크하여, 현재 몇 번째로 실행되는지 알 수 있다.
이를 실행하는 호출 방법은 다음과 같다. CPU의 순차 처리와 비교해보자.
// CUDA kernel launch
add_kernel<<<1, SIZE>>>(dev_c, dev_a, dev_b);
// CPU
for(int i=0;i<SIZE;++i){
...
}CUDA kernel의 <<<1,SIZE>>> 부분이 CPU의 순차 처리에 대응되는 코드이다.
CUDA 관점에서 보면 threadIdx.x는 다음과 같이 나올 수 있다.

🏷 gpu-add.cu
이제 실제로 GPU를 이용한 vector addition을 구현해보자.
먼저 CUDA kernel function을 만들고 host에서 source data를 생성하자.
#include "./common.cpp"
// kernel program for device(GPU)
__global__ void add_kernel(int* c, const int* a, const int* b){
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
// main program for host(CPU)
int main(void){
//host-side data
const int SIZE = 5;
const int a[SIZE] = {1,2,3,4,5};
const int b[SIZE] = {10,20,30,40,50};
int c[SIZE] = {0};
위 코드는 GPU 실행 코드를 만든 것과 main memory에 source data를 만들어 저장한 코드이다.
그다음으로 RAM의 배열 데이터를 복사해서 받을 수 있는 VRAM의 배열 변수를 만들고, 실제로 이를 복사해 넣어보자.
// device-side data
int* dev_a = 0;
int* dev_b = 0;
int* dev_c = 0;
//allocate device memory. VRAM에 배열 선언
cudaMalloc((void**)&dev_a, SIZE*sizeof(int));
cudaMalloc((void**)&dev_b, SIZE*sizeof(int));
cudaMalloc((void**)&dev_c, SIZE*sizeof(int));
//copy from host to device
cudaMemcpy(dev_a, a, SIZE*sizeof(int), cudaMemcpyHostToDevice); // dev_a = a;
cudaMemcpy(dev_b, b, SIZE*sizeof(int), cudaMemcpyHostToDevice); // dev_b = b;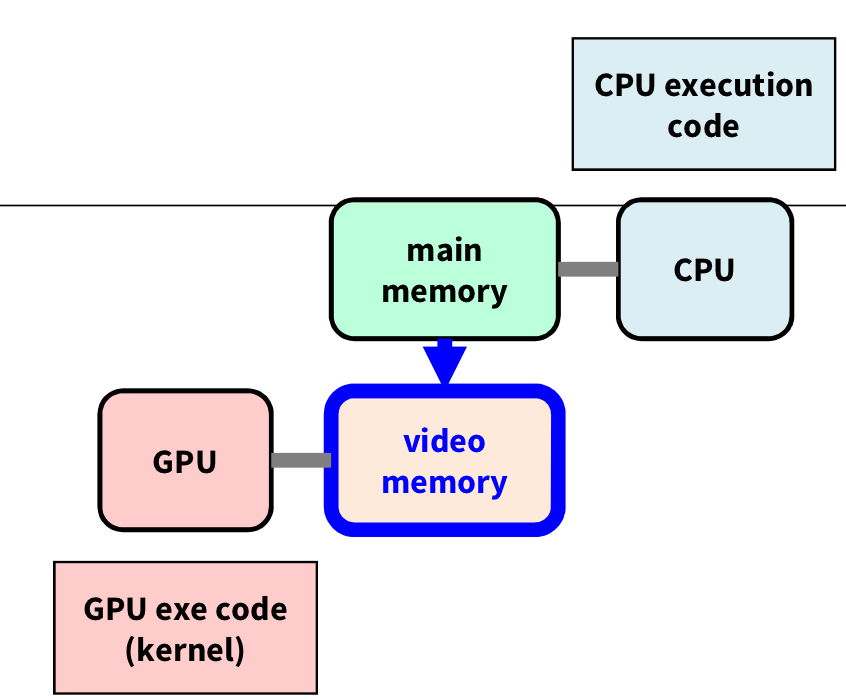
이 코드는 VRAM에 배열을 선언하여 host로부터 배열을 복사받은 것이다.
이제 Host(CPU)에서 kernel function을 호출(Call)하여 Kernel Launch를 해보자.
// launch a kernel on the GPU with 1 thread for each element
add_kernel<<<1,SIZE>>>(dev_c, dev_a, dev_b); // dev_c = dev_a + dev_b;
cudaDeviceSynchronize();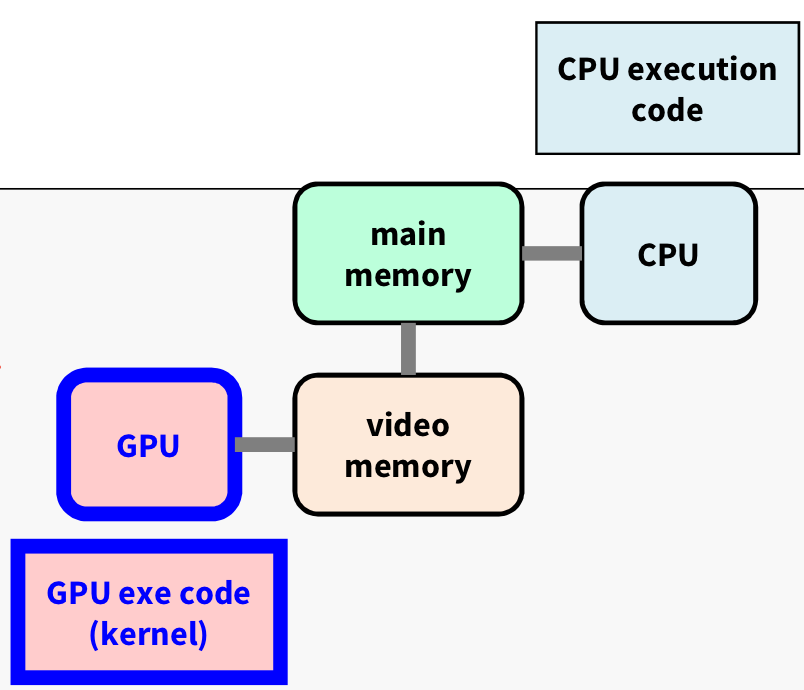
add_kernel 함수 내부에서 각각의 kernel 함수들은 threadIdx.x를 통해 자신의 인덱스를 찾아 대응되는 계산을 수행한다.
마지막의 cudaDeviceSynchronize()는 실행 중인 모든 Kernel 함수가 완료되는 것을 기다리는 것이다. 즉, kernel이 완전히 수행된 것을 정리하는 역할을 한다.
이제 병렬 처리를 통해 나온 결과를 Host의 C 배열에 복사해주자.
// copy from device to host
cudaMemcpy(c, dev_c, SIZE*sizeof(int), cudaMemcpyDeviceToHost); // c = dev_c;
// free device memory
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);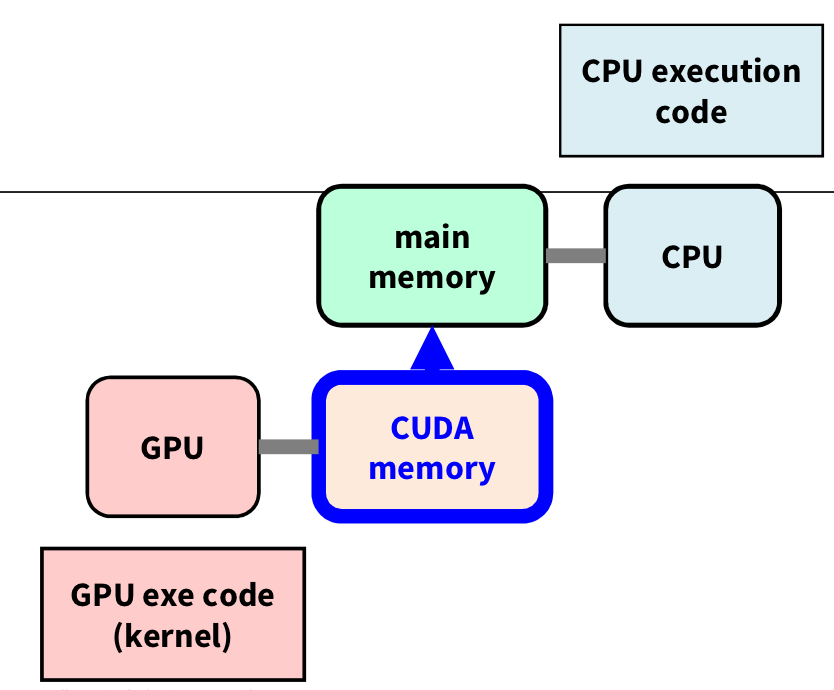
결과를 C 배열로 복사하고, 사용이 끝난 CUDA의 VRAM의 메모리를 Free 해준다.
마지막으로 host에서 출력해주면 gpu-add.cu 코드는 끝이 난다.
printf("{%d, ....", a[0],a[1], ... ,c[0],c[1], ... ,c[4]);
fflush(stdout);
return 0;
}
📂 Kernel Error Check
kernel을 Launch 했을 때, CUDA kernel 안에서도 에러가 발생할 수 있다.
하지만, Kernel function은 정의 자체가 반드시 void 함수이기 때문에 어떠한 error code로 return할 수 없다. 그래서 우리는 cudaPeekAtLastError() 함수를 이용한다.
📄 cudaPeekAtLastError()
cudeError_t cudaPeekAtLastError(void);위의 형태이며, 가장 마지막의 에러를 반환해준다.
add_kernel<<<1,SIZE>>>(...);
cudaError_t err = cudaPeekAtLastError();
if(cudaSuccess != err){
...
}
이와 같은 예제로 사용될 수 있는데, 여기서 err은 cudaPeekAtLastError를 실행했을 때 나오는 에러코드가 아니라, 이 이전에 실행한 kernel function 중 가장 마지막의 에러를 가져와 알려주는 것이다.
이 함수 호출이 일어난 뒤에 에러는 cudaSuccess로 리셋(reset)되지 않는다. 즉, 마지막 에러 코드가 여전히 살아있고, 그냥 마지막 에러 코드가 무엇인지 "확인"만 하는 것이다.
📄 cudaGetLastError()
cudaError_t cudaGetLastError(void);그럼 위에서 확인한 에러를 처리하고 싶을 때는 어떻게 할까? 그럴 때 사용하는 함수가 바로 cudaGetLastError이다.
이 함수는 Last error를 저장해 놓은 Error flag를 에러를 가져오고 난 뒤 cudaSuccess로 리셋해준다.
주의할 점은, 얼마나 많은 에러가 있건 무조건 마지막 에러만을 반환해준다는 것을 기억하자!
전체적인 로직을 보면,
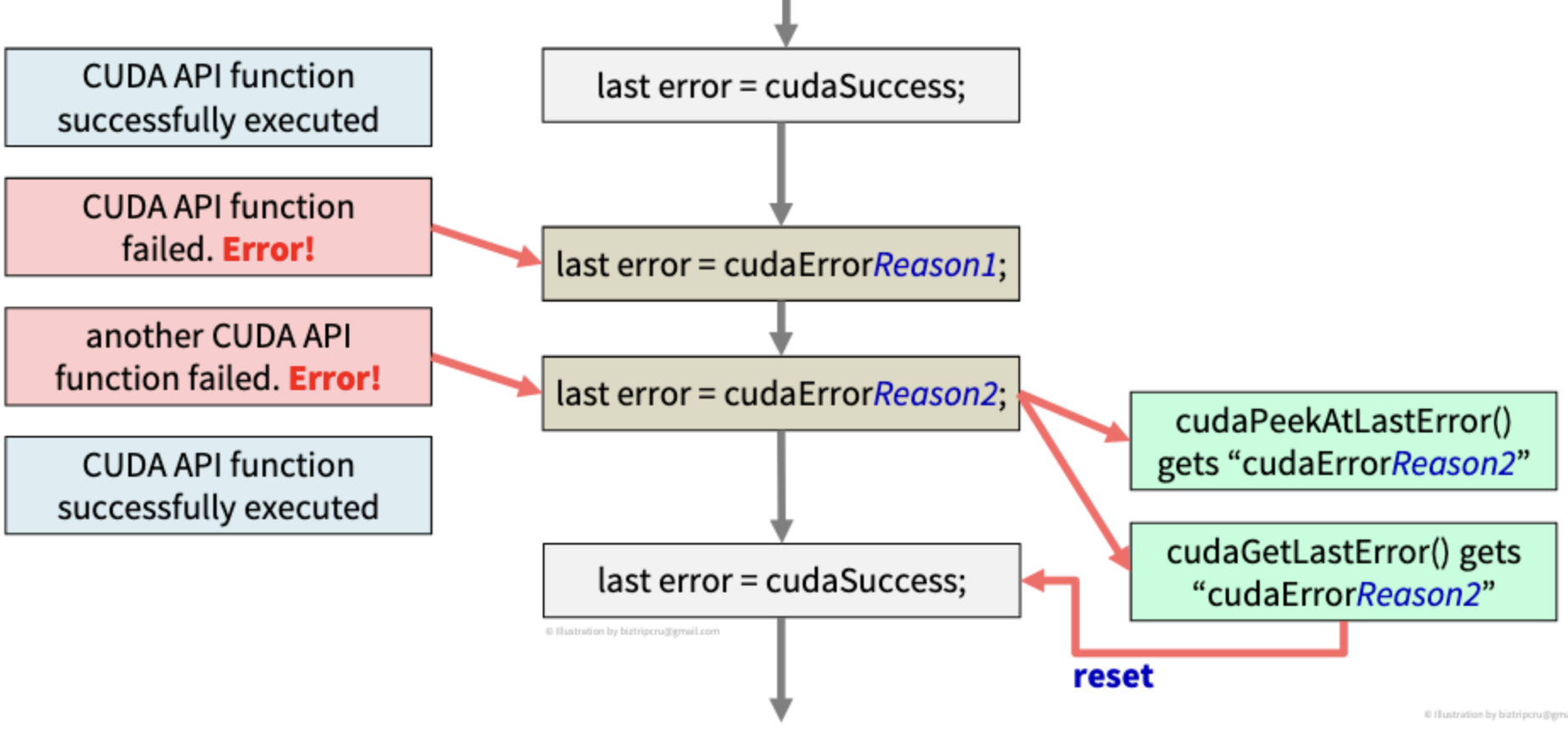
last error라는 CUDA 내부의 error flag가 존재하는데, 초기값은 cudaSuccess이고 에러가 발할 때마다 CUDA 시스템이 last error를 업데이트한다. 이 last error는 단 하나의 에러 코드만을 저장할 수 있다. 그래서 위의 그림에서와 같이 두 가지의 에러가 발생해도 마지막의 Reason2 에러만을 저장하게 된다. cudaPeekAtLastError는 Reason2라는 에러 코드"만"을 확인하는 것이고, 만약 이 에러 코드를 처리한 뒤, error flag를 cudaSuccess로 변경하고 싶다면, cudaGetLastError를 통해, 가져온 에러를 처리하고 reset 시키면 된다.
단순히 에러를 확인만 하고 싶다! → cudaPeekAtLastError()
발생한 에러를 처리해서 error flag를 정상(reset)으로 돌리고 싶다! → cudaGetLastError()
add_kernel<<<1,SIZE>>>(dev_c, dev_a, dev_b);
cudaDeviceSynchronize();
cudaError_t err = cudaPeekAtLastError();
if(cudaSuccess != err){
printf("CUDA: ERROR: cuda failure\"%s\"\n", cudaGetErrorString(err));
exit(1);
}
else{
printf("CUDA:success\n");
}이를 이용한 예제를 살펴보자.
+ 추가 설명
Q. 왜 CUDA kernel 함수는 void만 가능하고 error코드를 직접 return하지 않을까?
A. CPU는 단 1개의 return 값을 기대하는 반면, CUDA kernel은 100만개의 병렬 처리가 이루어지면, return값(error code) 또한 100만 개가 발생하기 때문이다.
Q. 그렇다면 계산 결과는 어떻게 알려줄까?
A. CUDA memory 영역의 배열/변수를 직접 update해야 한다. 즉, 특정 메모리 영역에 직접 결괏값을 쓰는 것이다.
__global void add_kernel(int* outC, const int* inA, const int* inB);
'대규모병렬컴퓨팅(MPC)' 카테고리의 다른 글
| [MPC/CUDA] Elapsed Time(시간 측정) (1) | 2022.10.13 |
|---|---|
| [MPC/CUDA] Error Check (0) | 2022.10.13 |
| [MPC/CUDA] CPU Kernel (0) | 2022.10.13 |
| [MPC/CUDA] Memory Copy (0) | 2022.10.13 |
| [MPC/CUDA] 대규모 병렬 컴퓨팅 개요 (3) | 2022.10.13 |