

CUDA를 설치했으니, CUDA 프로그래밍 모델과 CUDA 프로그램 시나리오에 대해 알아보자.
📂 CUDA 프로그래밍 모델
CUDA의 컴파일러 구조를 알아보기 전에 먼저 PC의 구조를 살펴보자.

pc의 구조를 도식화하면 위와 같이 나타낼 수 있다. 중앙에 위치한 north bridge, south bridge가 Controller Chip이며, 각각 memory controller, I/O controller의 역할을 한다. 왼쪽의 GPU가 들어있는 박스는 그래픽카드(비디오카드)의 부분이다.
이 PC 구조를 간략화해서 보자.
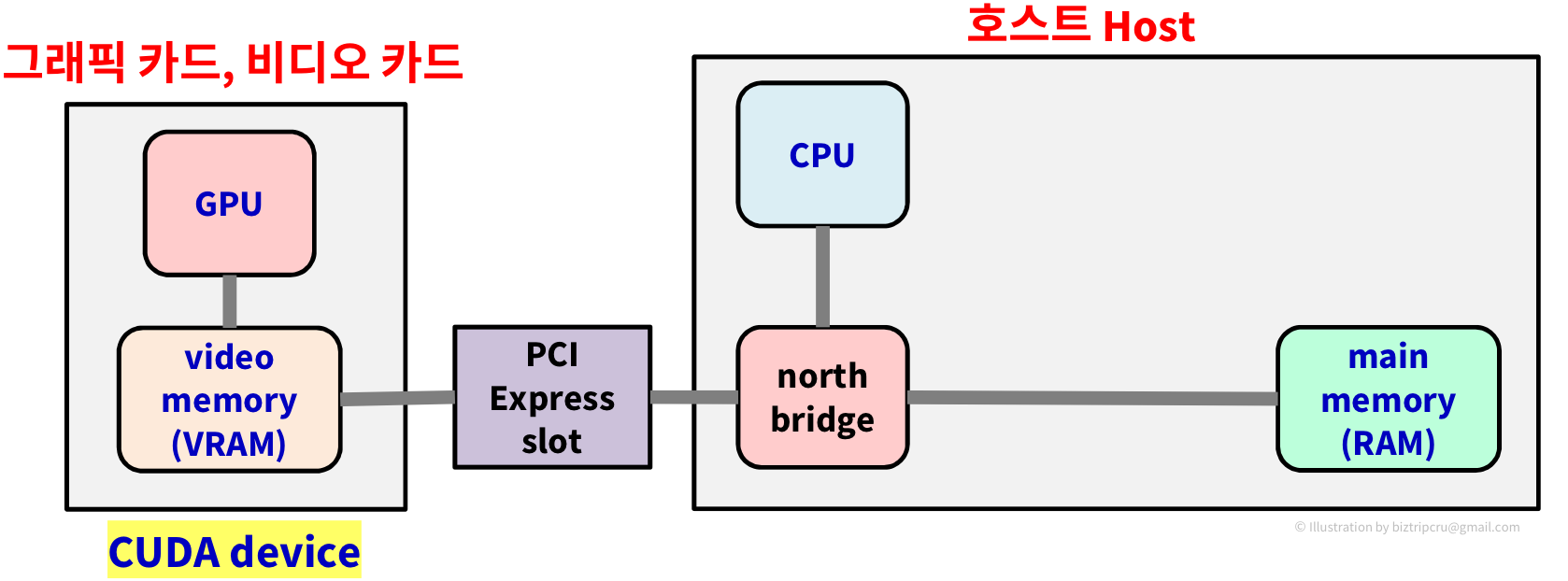
CUDA의 관점에서 그래픽 카드 쪽이 Device가 되고, CPU 쪽이 Host가 된다. 그리고, device와 host는 각각의 메모리를 가지고 있는데, CPU의 memory를 main memory, RAM, host memory... 등으로 부르고,
GPU의 memory를 video memory, VRAM, device memory... 등으로 부른다.

즉, 호스트(Host)는 CPU + main memory이고 디바이스(Device)는 GPU + video memory라고 볼 수 있다. 위의 그림에서 알 수 있듯이 CPU와 video memory 혹은 GPU와 main memory는 직접적인 연결이 불가능하다. 따라서, PCI-X bus를 이용해 데이터를 주고받아야 한다.
CUDA 컴파일러 구조
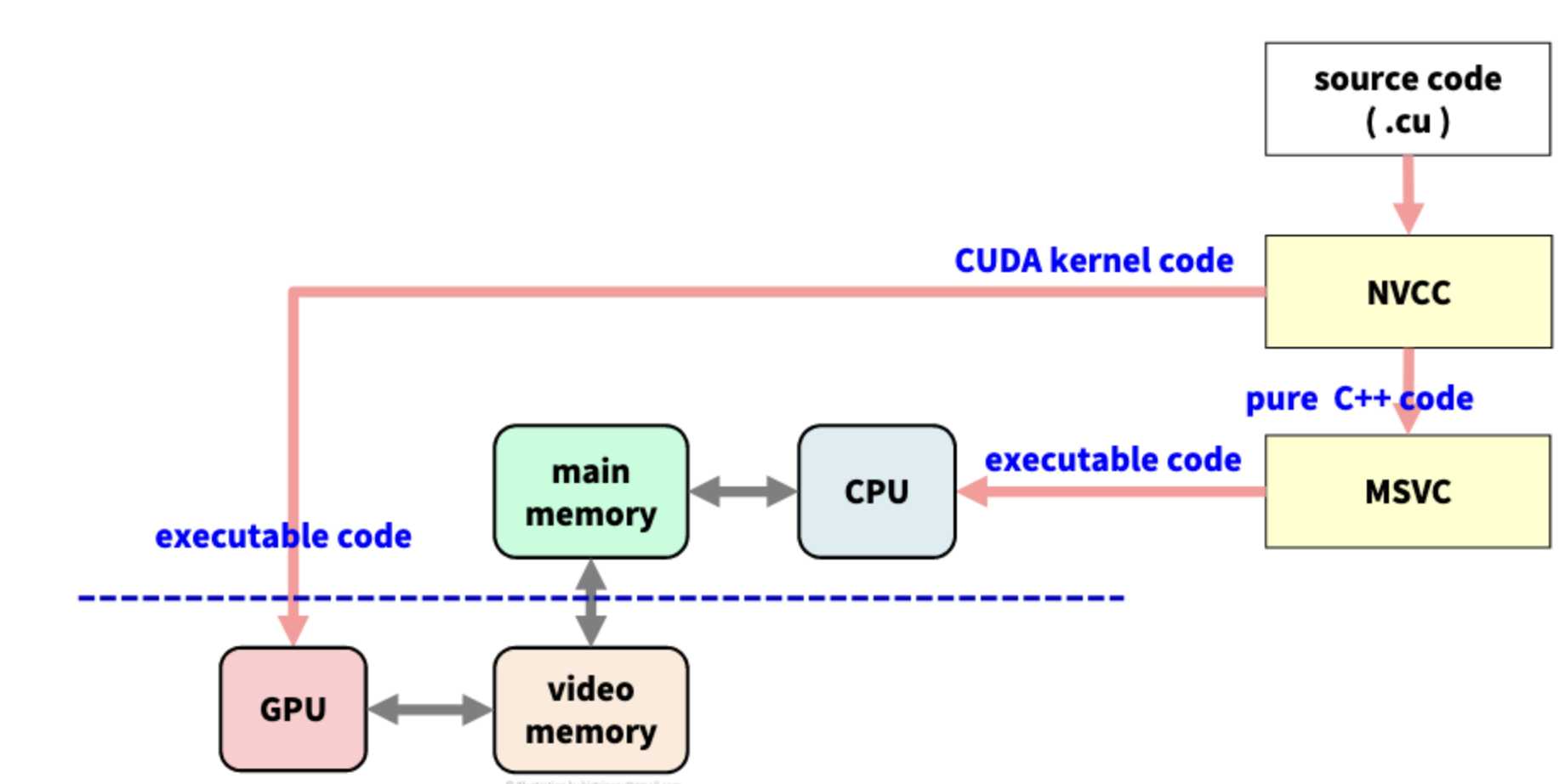
위의 그림은 CUDA 컴파일러의 구조를 도식화한 모습이다. *.cu 형식의 파일을 받으면 NVCC(NVIDIA CUDA Compiler)는 파일을 CUDA 코드와 순수한 C/C++ 코드를 분리하여, CUDA 코드는 실행 코드로 만들어 GPU로 보내고 순수한 C/C++ 코드는 MSVC(Microsoft Visual C++ Compiler)로 보낸다. C/C++ 코드를 받은 MSVC는 이를 실행 코드로 만들어 CPU로 전송한다.
즉, NVCC는 딱 CUDA function 부분만을 컴파일한다.
CUDA Kernel(커널)이란, GPU가 실행하는 작은 (병렬)프로그램을 말한다. 이때 CUDA가 사용하는 메모리는 video memory가 될 것이다. 주의할 점은, CUDA 커널은 직접적인 I/O가 불가능하다는 것이다. 아래 구조를 다시 살펴보자.

Hard disk 부분은 main memory와만 연결이 되어있는 것을 확인할 수 있다. 즉, Hard disk, keyborad, mouse... 등에서 입력을 받은 데이터는 일단 main memory로 가져온 다음, 이를 video memory로 copy 하여 CUDA가 처리하는 방식이다. video memory는 PCI-X bus와만 연결되어 있기 때문에 CPU를 통해야만 I/O 작업을 할 수 있는 것이다.
📂 CUDA 프로그램 시나리오
CUDA 프로그램을 실행하는 시나리오는 다음과 같다.
- 호스트(Host) CPU
- 외부 데이터 → 메인 메모리(Main memory)
- Main memory → Video memory (copy data via PCI-X Bus)
- 커널 프로그램(Device)
- CUDA kernel 실행
- Video memory의 데이터를 사용
- Video memory ↔ GPU로 병렬 처리 (이때, video memory만 필요하지, main memory는 필요 없다.)
- 처리 결과를 Video memory에 저장
- 호스트(Host) CPU
- Video memory → Main memory (copy result data via PCI-X Bus)
- 외부로 보내거나, I/O 출력
그림으로 보면 다음과 같다.
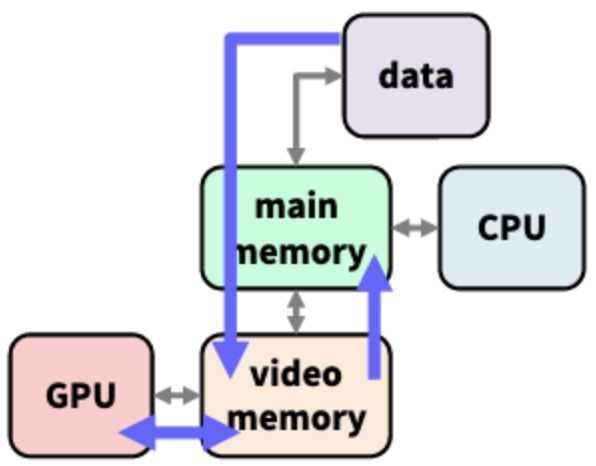
CUDA 그래픽 카드 내부 모델
CUDA 그래픽 카드는 여러 개의 GPU 프로세서와 글로벌 메모리(video memory)로 구성되어 있다.
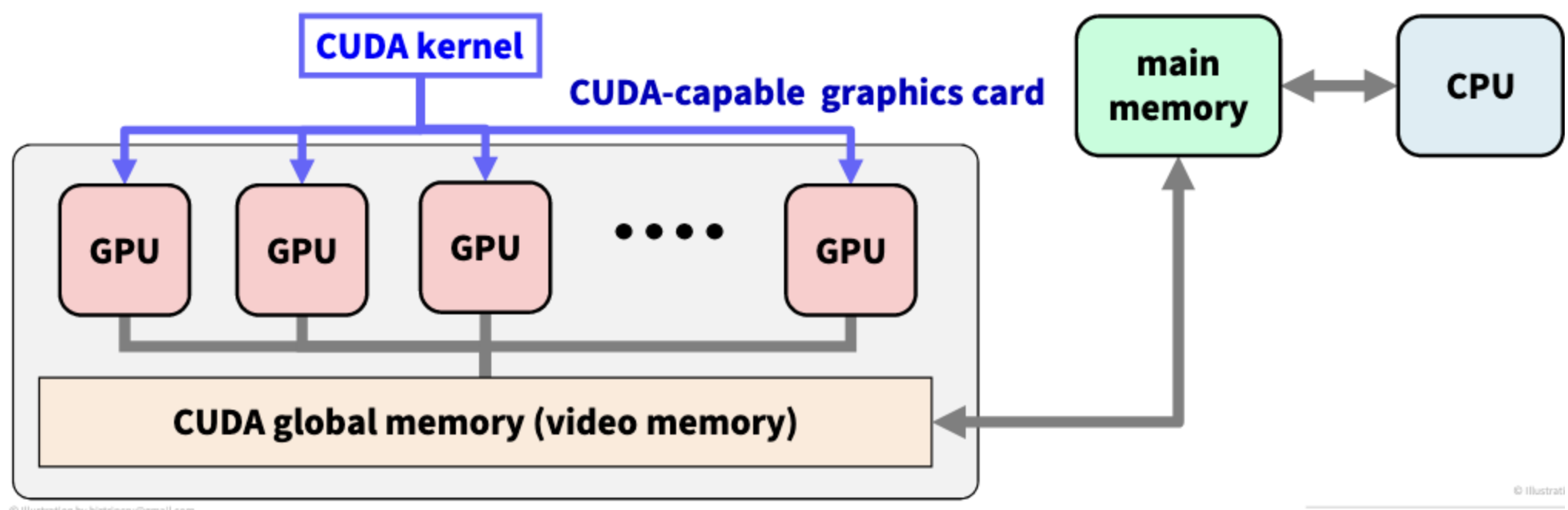
자세한 구조는 뒤에서 알아보고, 여러 개의 GPU 프로세서들이 하나의 video memory라는 글로벌 메모리를 공유하고 있다는 것만 보고 넘어가자.
📂 메모리 공간(Memory Space)
앞서 살펴본 것처럼, CPU와 GPU의 메모리 공간은 서로 분리되어 있다.
따라서, main memory를 할당/복사할 때는 C++함수를 사용하고, video memory를 할당/복사 할 경우에는 별도의 CUDA 함수를 사용해야 한다. 이제 이 video memory에 관련된 CUDA 함수를 알아보자.
주의할 점이 하나 있는데, video memory와 main memory의 주소가 다르기 때문에, 어떠한 주소값이 어느 쪽 메모리의 주소인지 잘 구분할 필요가 있다. 만약, 반대쪽 주소를 넣는다면(ex. video memory의 주소를 main memory에) 시스템 크러쉬가 발생한다.
이를 해결하기 위해, 보통 device에는 "dev_"를 붙인다.
CUDA 메모리 관련 함수
C/C++ 메모리 관련 함수(malloc, memset...)는 이미 알 것이라 생각하고 CUDA 메모리 함수만 설명하겠다.
우리가 주로 사용할 CUDA 메모리 함수는 아래와 같은 것들이 있다.
- cudaError_t cudaMalloc(void** dev_ptr, size_t nbytes);
- cudaError_t cudaMemset(void* dev_ptr, int value, size_t count);
- cudaError_t cudaFree(void* dev_ptr);
모든 CUDA 함수는 "cuda"로 시작한다. 또한, 대부분은 에러 코드(Error Code)를 리턴하고 성공 시에는 cudaSuccess를 리턴한다. 예를 들어 다음과 같이 사용할 수 있다.
if(cudaMalloc(&devPtr, SIZE) != cudaSuccess){
exit(1);
}
이제 함수 하나씩 자세하게 알아보자.
CUDA malloc
cudaError_t cudaMalloc(void** devPtr, size_t nbytes);- CUDA 메모리(video memory) 영역에 nbyte를 할당한다.
- 시작 주소는 devPtr에 저장된다.
- 메모리는 clear하지 않는다.
- 리턴 값 = cudaSuccess, cudaErrorMemoryAllocation
cudaError_t cudaFree(void* devPtr);- devPtr이 가리키는 메모리를 반환한다.
- devPtr==nullptr or devPtr==0 인 경우는 무시한다. 즉, cudaFree 함수 자체가 무시되는 것이다.
- 리턴 값 = cudaSuccess, cudaErrorInvalidDevicePointer(main memory의 주소를 넣은 경우)
CUDA memset
cudaError_t cudaMemset(void* devPtr, int value, size_t nbytes);- devPtr이 가리키는 영역의 최초 nbytes를 value로 설정하는 함수이다.
- byte 단위로 설정된다.
- value = 0 → 모든 byte가 0으로 (clear)
- value = 0x77 → 모든 byte가 0x77, 4byte는 0x77777777로 설정 (보통 디버깅의 용도로 사용된다.)
- 리턴 값 = cudaSuccess, cudaErrorInvalidValue, cudaErrorInvalidDevicePointer
CUDA memcpy
cudaError_t cudaMemcpy(void* dst, void* src, size_t nbytes, enum cudaMemcpyKind direction);어쩌면 가장 많이 사용되고 중요한 함수라고 할 수 있다. 잘 알아두자!
- 이전 CUDA 함수들이 모두 종료되어야 복사가 시작된다.
- copy 중에는 CPU 스레드도 정지되고, 작업이 완료되어야 리턴된다.
- direction은 복사하는 종류(방향)를 결정한다.
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyHostToHost

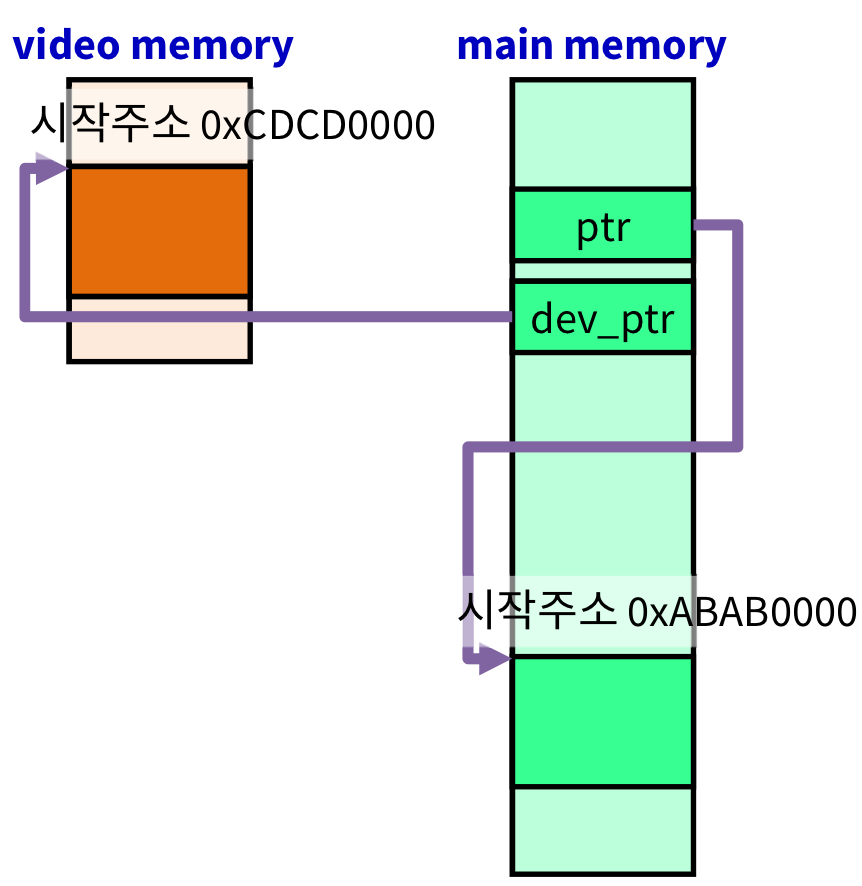
메모리 공간
int* ptr = nullptr;
int* dev_ptr = nullptr;
ptr = malloc(nbytes);
cudaMalloc((void**)&dev_ptr, nbytes);위와 같이 정의한 포인터 변수(ptr, dev_ptr)는 main memory에 위치한다. 하지만, 할당받는 공간은 함수 별(malloc, cudaMalloc)로 다르다.
cudaMalloc으로 실행된 dev_ptr은 video memory의 주소를 가리킨다.
그림으로 보면 다음과 같다.
위의 전체 내용을 예제 코드를 통해 확인해보자.
#include <stdio.h>
int main(void){
//host-side data
const int SIZE = 8;
const float a[SIZE] = {1,2,3,4,5,6,7,8}; // SRC
float b[SIZE] = {0.,); // DST
//print source
printf("a={%f,%f,%f,%f,%f,%f,%f,%f}\n", a[0], a[1], a[2], a[3], a[4], a[5], a[6], a[7]);
fflush(stdout);
//device(cuda)-side data
float* dev_a = nullptr;
float* dev_b = nullptr;
//allocate device memory
cudaMalloc((void**)&dev_a, SIZE*sizeof(float));
cudaMalloc((void**)&dev_b, SIZE*sizeof(float));
//3 copies
cudaMemcpy(dev_a, a, SIZE*sizeof(float), cudaMemcpyHostToDevice); //dev_a = a
cudaMemcpy(dev_b, dev_a, SIZE*sizeof(float), cudaMemcpyDeviceToDevice); //dev_b = dev_a
cudaMemcpy(b, dev_b, SIZE*sizeof(float), cudaMemcpyHostToDevice); //b = dev_b
//free device memory
cudaFree(dev_a);
cudaFree(dev_b);
//print the result
printf("b={%f,%f,%f,%f,%f,%f,%f,%f}\n", b[0], b[1], b[2], b[3], b[4], b[5], b[6], b[7]);
fflush(stdout);
return 0;
}실행 결과를 확인해보면 다음과 같다.

a → dev_a →dev_b → b 로 정상적으로 복사가 이루어진 것을 확인할 수 있다.
'대규모병렬컴퓨팅(MPC)' 카테고리의 다른 글
| [MPC/CUDA] Elapsed Time(시간 측정) (1) | 2022.10.13 |
|---|---|
| [MPC/CUDA] Error Check (0) | 2022.10.13 |
| [MPC/CUDA] CUDA Kernel (0) | 2022.10.13 |
| [MPC/CUDA] CPU Kernel (0) | 2022.10.13 |
| [MPC/CUDA] 대규모 병렬 컴퓨팅 개요 (3) | 2022.10.13 |