

이 전 포스팅에서 본 CUDA 컴파일러의 구조를 좀 더 자세히 보자.
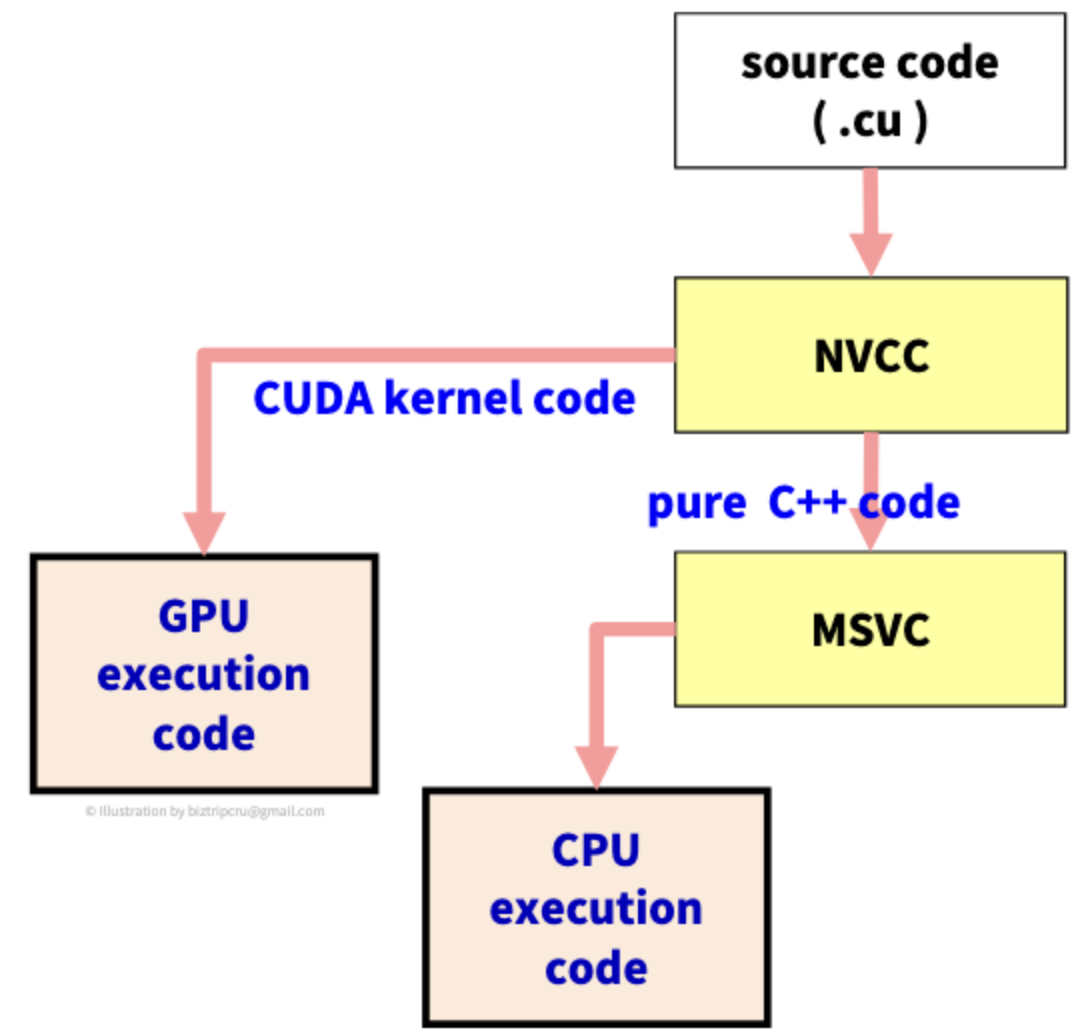
source code에는 CUDA kernel 코드와 C++ 코드가 함께 섞여 있다. 그렇다면, CUDA 컴파일러 입장에서 source code에서 어느 부분이 CPU를 위한 코드이고, 어느 부분이 GPU를 위한 코드인지 구분할 필요가 있다.
이를 구분하는 단위를 the unit of compilations라 한다. file 단위, line 단위... 등 여러 가지 단위가 있지만, 우리는 function 즉, 함수 단위를 사용할 것이다.
📂 CUDA programming model
CUDA 컴파일러에서 compilation unit은 functions 이다. 각 함수들이 CPU나 GPU에 할당될 것이다. 그럼 함수들을 구분하는 방법은 무엇일까?
각 함수마다 PREFIX를 사용한다.
- __host__
- CPU에 의해 호출된다.
- default값이며, 생략이 가능하다.
- __device__
- 다른 GPU의 함수들이 호출하며, CPU에 의해서는 호출될 수 없다.
- __global__
- GPU에서 실행할 수 있지만 실행은 Launch 하는 것 즉, 실행하도록 호출(Call)해주는 것은 CPU이다.
- 반드시 void를 return 한다.
__host__는 CPU가 처리하고, __device__와 __global__은 GPU가 처리한다.
__host__와 __device__는 같이 사용될 수 있다.
이 PREFIX들에 대해서 자세하게 알아보자.
🏷 __global__
__global__은 kernel function을 정의한다.(_가 2개)
Kernel function은 반드시 void를 리턴한다.
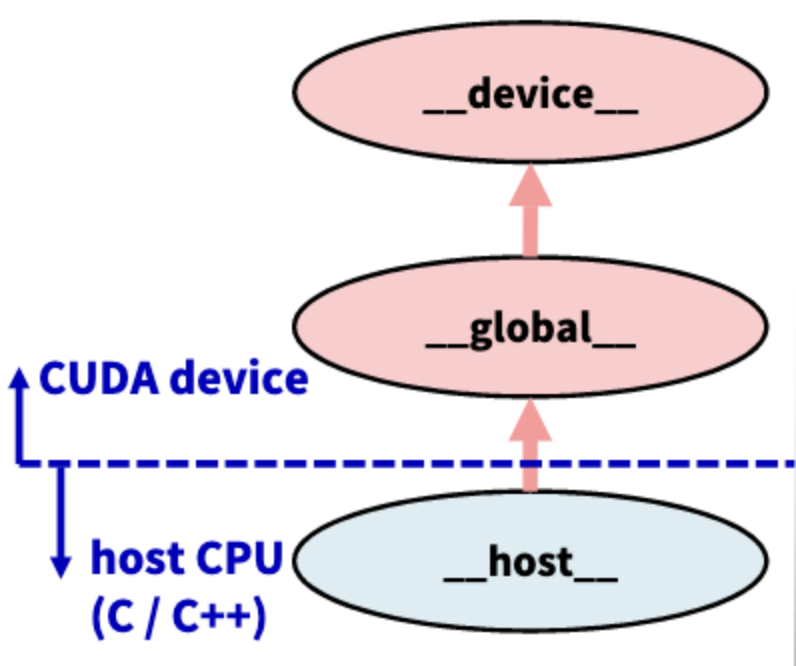

위의 그림과 표를 살펴보자.
__device__는 CUDA 내에서 다른 CUDA function들을 Call 하는 경우 사용된다.
__global__은 host에서 call한 것을 CUDA에서 실행할 경우 사용된다. 즉, CPU에서 CUDA한테 이제 CUDA가 일을 해라~ 하며 제어를 넘길 때 사용되는 것이다.
예제 코드를 보자.
__device__ inline void myAtomicAdd(...){
...
}
__global__ void kernel(...){
myAtomicAdd(...);
}
__host__ int main(void){
...
//main함수 어딘가에서 __globa__ 함수 호출
}먼저, main 함수 안 어딘가에서 __global__ 함수를 호출(Call)할 것이다. 그럼 __global__인 함수 'kernel'이 실행되면서 __device__를 호출할 것이다. 이 과정은 CUDA에서 CUDA를 Call 한 경우가 된다.
CUDA language는 몇 가지 제약사항을 가지고 C/C++ language와 비슷하다.
- GPU memory(VRAM)만 접근할 수 있다.
- static variable(static 변수)을 가질 수 없다.
- recursion(재귀호출)이 불가능하다.
- Dynamic polymorphism이 불가능하다.
📂 Vector addition
C[i] = A[i] + B[i]처럼 1차원 배열의 합을 새로운 1차원 배열에 넣는 연산을 CPU만 사용하는 방법과 CUDA를 사용하는 방법을 이용해 구현해보자.
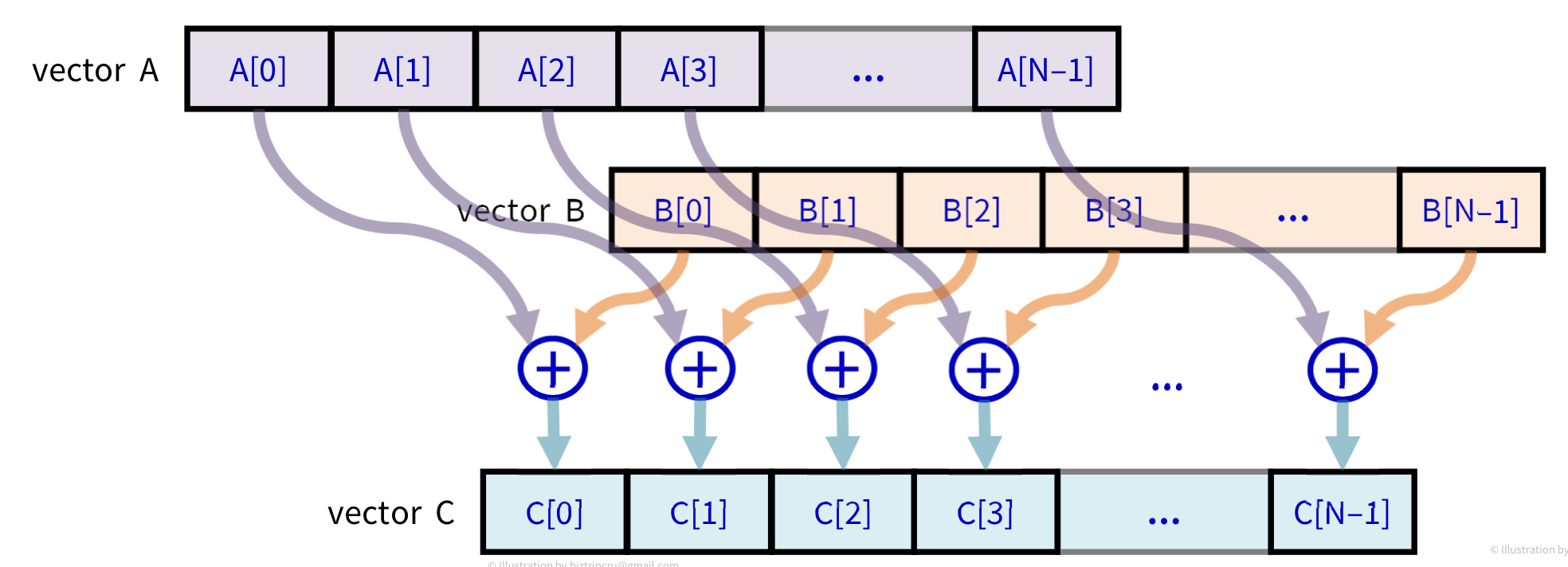
위와 같은 로직으로 실행이 될 것이다.
일반적인 CPU로 실행하는 방법은 for-loop문을 수행하는 것이고 CUDA를 사용하면 parallel kernel 실행이 될 것이다.
🏷 cpu-add.cu
먼저, CPU만을 사용하는 방법이다. for-loop 사용
int main(void){
const int SIZE = 5;
const int a[SIZE] = {1,2,3,4,5};
const int b[SIZE] = {10,20,30,40,50};
int c[SIZE] = {0};
for(register int i=0;i<SIZE;++i){
c[i] = a[i] + b[i]; // Body
}
printf(...);
return 0;
}이렇게 for-loop문을 사용하면, single CPU는 SIZE만큼 일을 수행하게 된다.
🏷 cpu-kernel.cu
이 코드는 CPU에서 커널(kernel)을 이용하는 방법이다.
먼저 Kernel이란, Loop에서 Body부분을 말한다. 이를 함수로 떼어내어 따로 표현한다면 Kernel function이 되는 것이다.
// Kernel Function
void add_kernel(int idx, const int* a, const int* b, int* c){
int i=idx;
c[i]=a[i]+b[i];
}
int main(void){
....
for(register int i=0;i<SIZE;++i){
add_kernel(i,a,b,c);
}
...
return 0;
}이 커널 함수의 동작 과정을 살펴보면 다음과 같다.

만일 Single CPU일 경우, 각 time마다 add_kernel 함수가 한 번씩 수행되어 SIZE time에 끝나게 된다. 즉, 순차 처리(Sequential Execution)을 하게 된다.

하지만 위와 같이 Multi-core CPU라면 어떻게 될까? Core가 2개 있기 때문에 각 time마다 2번의 add_kernel 함수를 실행할 수 있다. 즉, 두 개의 코어가 같은 순간에 일을 동시에 수행할 수 있는 것이다. 이는 병렬 처리(Parallel execution)라고 할 수 있다.
그렇다면 여기서 더 나아가 GPU에 매우 많은 코어(Many-core GPU)가 있는 경우는 어떻게 될까?

GPU의 코어 수가 실행할 함수보다 많다고 가정해보면, time 0에 모든 add_kernel 함수의 실행을 마칠 수 있을 것이다. 이를 massively parallel execution이라 한다. 진정한 대규모 병렬 처리인 것이다!
다음 포스팅부터 GPU kernel에 대해 자세히 알아보자.
'대규모병렬컴퓨팅(MPC)' 카테고리의 다른 글
| [MPC/CUDA] Elapsed Time(시간 측정) (1) | 2022.10.13 |
|---|---|
| [MPC/CUDA] Error Check (0) | 2022.10.13 |
| [MPC/CUDA] CUDA Kernel (0) | 2022.10.13 |
| [MPC/CUDA] Memory Copy (0) | 2022.10.13 |
| [MPC/CUDA] 대규모 병렬 컴퓨팅 개요 (3) | 2022.10.13 |