

📂 데이터와 정보
우리는 간혹 데이터(Data)와 정보(Information)를 혼돈해서 사용하는데, 엄격하게 둘은 다른 의미이다.
데이터(Data)
현실 세계로부터 단순한 관찰이나 측정을 통해서 수집된 사실(Facts)이나 값(Values)이다. 데이터는 숫자는 물론이고 문자(Text), 이미지(Image), 영상(Video) 등을 포함한다.
그 자체만으로는 의미가 없는 단순한 숫자나 문자. 처리되지 않은 값.
정보(Information)
의사결정을 할 수 있게 하는 지식으로서 데이터의 유효한 해석(interpretation)이나 데이터 상호간의 관계(relationship)를 말한다.
정보는 데이터를 처리해서 얻은 결과
정리하면, 데이터는 처리하지 않은 값인 반면, 정보는 데이터를 처리하여 얻은 값이다.
공식적으로 표현하면 $I=P(D)$ 이다.

데이터 $D$를 처리기$P$가 처리하여 결과가 $I$인 정보를 산출한다는 의미이다. 이 정보 추출 방법을 데이터 처리(Data processing) 또는 정보 처리(Information processing)이라고 한다.
📂 정보 시스템(Information System)
정보 기술을 이용하여 조직 활동에 필요한 데이터를 수집, 조직, 저장 그리고 정리하여 의사 결정에 필요한 정보를 추출하고 제공하는 수단이다.
한 조직체의 내부적 운영과 외부적 상황에 관련된 정보를 체계적으로 제공하는 시스템이다.
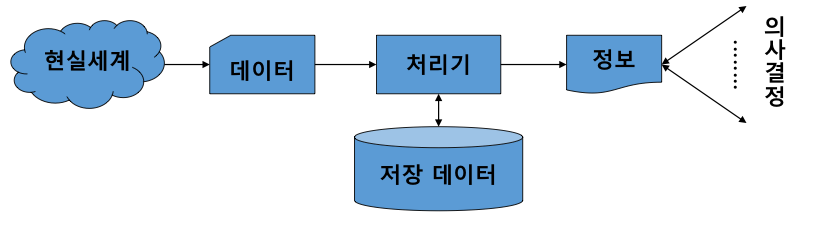
위 그림은 현실 세계에 존재하는 데이터를 수집, 조직하여 정보 시스템을 구축하고 이를 처리하여 얻은 정보가 의사 결정에 사용되는 과정을 보여주고 있다.
※ 정보 시스템 중에서 특히 기업의 경영관리를 지원하는 정보 시스템을 경영정보 시스템(MIS : Management Information System)이라고 한다.
사용 목적에 따른 정보 시스템의 분류
정보 시스템을 사용 목적에 따라 분류해 본다면 다음과 같다.
- 생산 관리 시스템(Manufacturing Management System)
- 은행 관리 시스템(Bank Management Ssytem)
- 병원 관리 시스템(Hospital Management System)
- 의사 결정 지원 시스템(DSS : Decision Support System)
- 전문적인 목적보다는 여러 가지 다양한 형태의 조직 의사 결정을 지원하는 통합적인 정보 시스템
- 지식 관리 시스템(Knowledge Management System)
- 데이터를 사람이 학습하듯이 컴퓨터도 학습시켜 더 수준 높은 지식을 도출하고 관리하여 활용하는 정보 시스템
데이터 웨어하우스(Data Warehouse)
다양한 소스의 데이터로부터 의사 결정 지원을 제공하는 시스템을 말한다. 주로 다차원에 대한 다차원 구조를 보여준다.
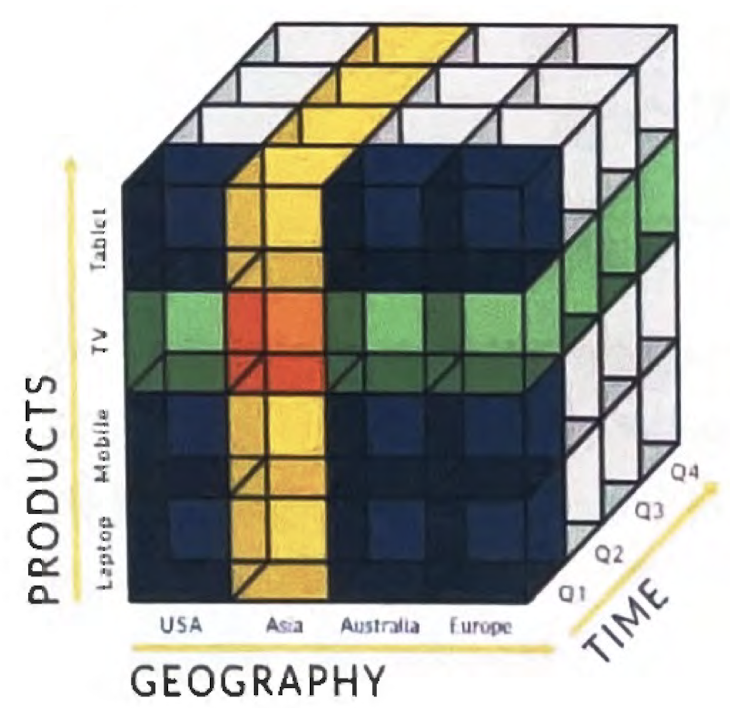
이러한 복잡한 다차원 데이터로부터 의미 있는 지식을 발견하는 과정을 데이터마이닝(Data mining)이라 한다. 결과를 대략적으로 추측하는 것이 아니라 통계나 인공지능을 사용하여 몇 % 관련 있는지 산출하는 알고리즘을 개발하는 것이다.
📂 데이터 처리 시스템(Data Processing System)
정보 시스템은 실제로 데이터를 처리하는 데이터 처리 시스템을 기초로 구성된다.
데이터 처리 시스템은 데이터 처리 형태에 따라 다음 3가지 시스템으로 구분할 수 있다.
일괄 처리 시스템(Batch Processing System)
일괄 처리는 실시간(real-time)으로 처리되는 것이 아니라
입력 데이터를 한꺼번에 모아 두었다가 한 번에 처리하는 시스템
번호와 같이 순차 접근 방법(Sequential access method)을 사용하는 업무에 적합하다. 예로는, 급여 명세서, 납세 고지서 등이 있다.
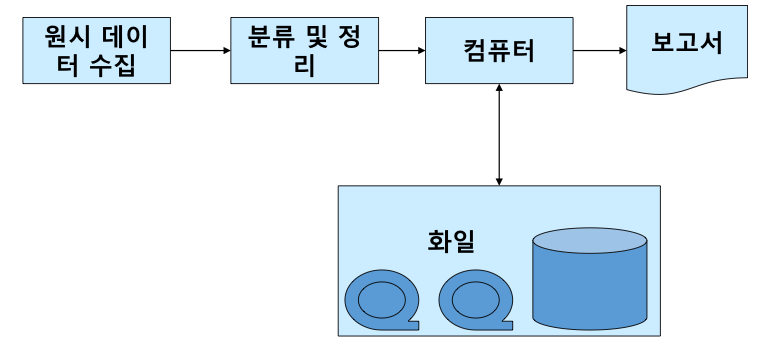
일괄 처리 시스템의 장점으로는,
- 작업을 한데 모아 일괄적으로 처리하기 때문에, 작업을 처리하는데 드는 처리 비용이 낮다.
- 모아 놓은 데이터를 짧은 시간에 쉴 새 없이 한꺼번에 작업을 처리할 수 있으므로, 단위시간당 작업 수가 많게 되어 시스템 성능을 높일 수 있다.
하지만, 단점으로는,
- 한꺼번에 작업을 처리하기 위해 사전에 데이터를 한 곳으로 계속 수집해야 할 일이 필요하다.
- 이들을 분류하고, 분류된 데이터를 처리하는 등 사전에 여러 가지 사전 준비 작업을 거쳐야 한다.
실시간 처리 시스템(Real-time Processing System)
일괄 처리 방식에서 필요했던 사전 준비 작업 필요 없이
곧바로 데이터를 처리하는 방식의 시스템
데이터 생성 후 곧바로 컴퓨터에 전송되고 전송된 데이터는 컴퓨터가 즉시 처리해서 그 결과를 원하는 장소로 보내주는 시스템이다.
예를 들어, 항공권 좌석 예약, 은행 입출금 업무 ... 등이 있다.
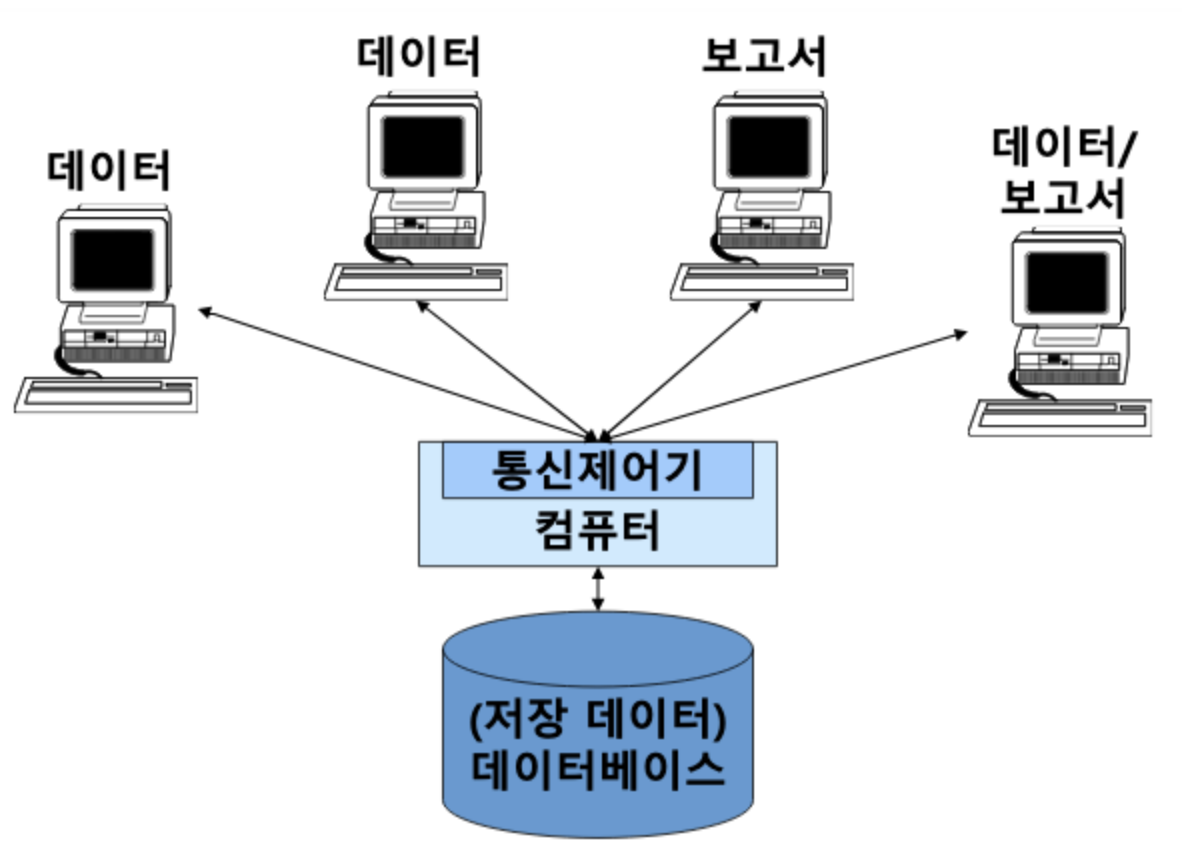
실시간 처리 방식은 사용자에게 대기 시간 없이 즉시 응답해준다. 그리고 데이터가 저장된 곳을 중심으로 그 기능들이 집중되는 중앙 집중 시스템이다. 하지만 이는, 데이터가 지리적으로 분산되어 있는 환경에서는 효과적인 처리 방법이 되지 못한다.
이런 의미에서 일괄 처리 방식은 시스템 중심적인 처리 방식이라 할 수 있고, 실시간 처리 방식은 사용자 중심 처리 방식이라 할 수 있다.
실시간 처리 시스템의 장점으로는,
- 데이터 입력에 대하여 분류나 정리 작업 등이 거의 필요 없게 되었다.
- 어떤 순간에 오류가 발생하면 바로 찾을 수 있다.
- 오류 발견 즉시 바로 수정도 가능하다.
- 질의/검색/갱신이 가능하기 때문에 데이터의 최신성을 편리하게 유지할 수 있다.
단점으로는,
- 많은 원격 터미널들과 계속적인 통신을 유지해야 하고 이를 위한 통신 제어기가 필요하기 때문에 구조가 복잡하게 된다.
- 응답 시간을 최소화해야 하기 때문에, 작업당 처리 비용이 높게 된다.
- 시스템이 항상 작동되어야 하므로 프로그램 테스트나 시스템 유지보수가 어렵다.
- 회복(원래 상태로 되돌리는 작업)이 매우 복잡하다.
분산 처리 시스템(Distributed Processing System)
분산 처리 시스템은
네트워크로 연결시켜 마치 하나의 시스템처럼 데이터를 처리하는 시스템
모든 지역들을 통신 네트워크로 연결하여 각 지역에서 수행한 작업들을 통합하여 원하는 결과를 얻는 시스템이다.
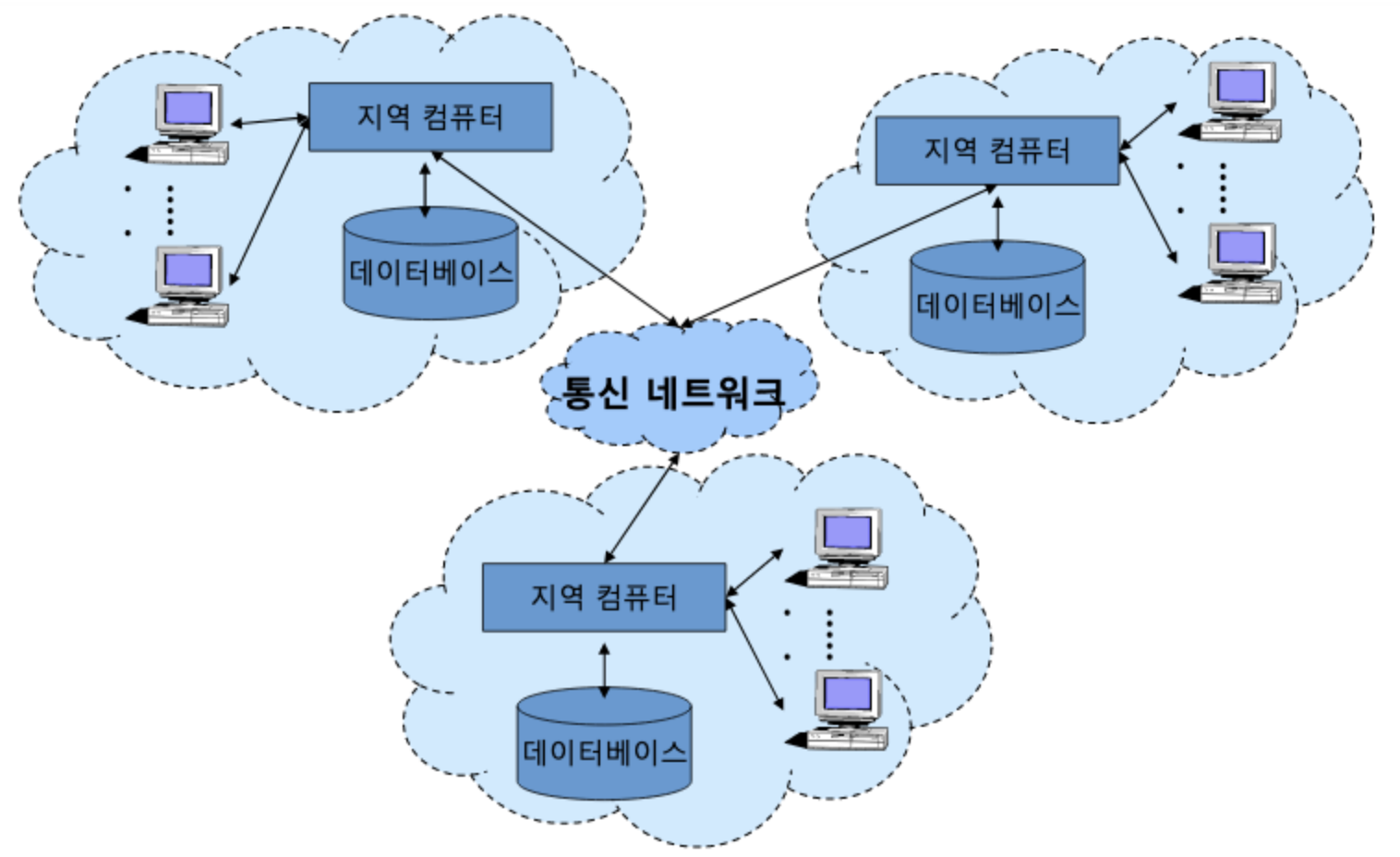
분산 데이터베이스에서 데이터는 가장 많이 이용되는 장소에 저장된다. 그러나 사용자 입장에서는 네트워크 내의 모든 데이터는 논리적으로 마치 하나의 데이터베이스에서 처리되는 것처럼 투명성을 제공해 주어야 한다.
통신 네트워크는 마치 하나의 시스템을 사용하는 것처럼 데이터를 처리해 주는 시스템이다.
분산 처리 시스템의 이점으로는,
- 지역 문제 발생에 대한 신속한 조치
- 문제가 발생한 곳에서 처리하면 신속한 조치 가능
- 지역 업무에 대한 명확한 책임 구분
- 지역 업무는 그 지역에서 처리
- 새로운 응용에 대한 모듈식 구축 용이
- 예를 들어, 새로운 지점이 개설되면 지점을 하나 더 개설하여 통신 네트워크로 연결하면 시스템을 쉽게 구현할 수 있다.
- 장애에 대한 자원 재편성으로 신뢰성 증대
- 지역 컴퓨터 하나가 고장나면 다른 컴퓨터로 대체하여 처리할 수 있다. 이로 인해 자연히 신뢰도가 높아진다.
- 상이한 하드웨어 허용으로 지속적 확장 발전 가능
- 각 지역 컴퓨터는 같은 종류의 하드웨어로 구성될 필요가 없다.
'데이터베이스' 카테고리의 다른 글
| [데이터베이스] SQL(Structured Query Language) - 1 (0) | 2022.11.26 |
|---|---|
| [데이터베이스] 데이터베이스 모델링 (0) | 2022.10.18 |
| [데이터베이스] 데이터베이스 시스템 (0) | 2022.10.18 |
| [데이터베이스] DBMS (0) | 2022.10.15 |
| [데이터베이스] 데이터베이스 정의 (0) | 2022.10.15 |